ISWC 2018 Trip Report Keynotes There were three amazing and inspiring keynote talks, all very different from each other. The first was given by Jennifer Golbeck (University of Maryland). While Jennifer did her PhD on the Semantic Web in the early days of social media and Linked Data, she now focuses on user privacy and […]
ISWC 2018 Trip Report
Keynotes
There were three amazing and inspiring keynote talks, all very different from each other.
The first was given by Jennifer Golbeck (University of Maryland). While Jennifer did her PhD on the Semantic Web in the early days of social media and Linked Data, she now focuses on user privacy and consent. These are highly relevant topics to the Semantic Web community and something that we should really be considering when linking people’s personal data. While the consequences of linking scientific data might not be as scary, there are still ethical issues to consider if we do not get it right. Check out her TED talk for an abridged version of her keynote.
She also suggested that when reading a companies privacy policy, you should replace the work “privacy” with “consent” and see how it seems then.
The talk also struck an accord with the launch of the SOLID framework by Tim Berners-Lee. There was a good sales pitch of the SOLID framework from Ruben Verborgh in the afternoon of the Decentralising the Semantic Web Workshop.
The second was given by Natasha Noy (Google). Natasha talked about the challenges of being a researcher and engineering tools that support the community. Particularly where impact may only be detect 6 to 10 years down the line. She also highlighted that Linked Data is only a small fraction of the data in the world (the tip of the iceberg), and it is not appropriate to expect all data to become Linked Data.
Her most recent endeavour has been the Google Dataset Search Tool. This has been a major engineering and social endeavour; getting schema.org markup embedded on pages and building a specialist search tool on top of the indexed data. More details of the search framework are in this blog post. The current search interface is limited due to the availability of metadata; most sites only make title and description available. However, we can now start investigating how to return search results for datasets and what additional data might be of use. This for me is a really exciting area of work.
Later in the day I attended a talk on the LOD Atlas, another dataset search tool. While this gives a very detailed user interface, it is only designed for Linked Data researchers, not general users looking for a dataset.
The third keynote was given by Vanessa Evers (University of Twente, The Netherlands). This was in a completely different domain, social interactions with robots, but still raised plenty of questions for the community. For me the challenge was how to supply contextualised data.
Knowledge Graph Panel
The other big plenary event this year was the knowledge graph panel. The panel consisted of representatives from Microsoft, Facebook, eBay, Google, and IBM, all of whom were involved with the development of Knowledge Graphs within their organisation. A major concern for the Semantic Web community is that most of these panelists were not aware of our community or the results of our work. Another concern is that none of their systems use any of our results, although it sounds like several of them use something similar to RDF.
The main messages I took from the panel were
-
Scale and distribution were key
-
Source information is going to be noisy and challenging to extract value from
-
Metonymy is a major challenge
This final point connects with my work on contextualising data for the task of the user [1, 2] and has reinvigorated my interest in this research topic.
Final Thoughts
This was another great ISWC conference, although many familiar faces were missing.
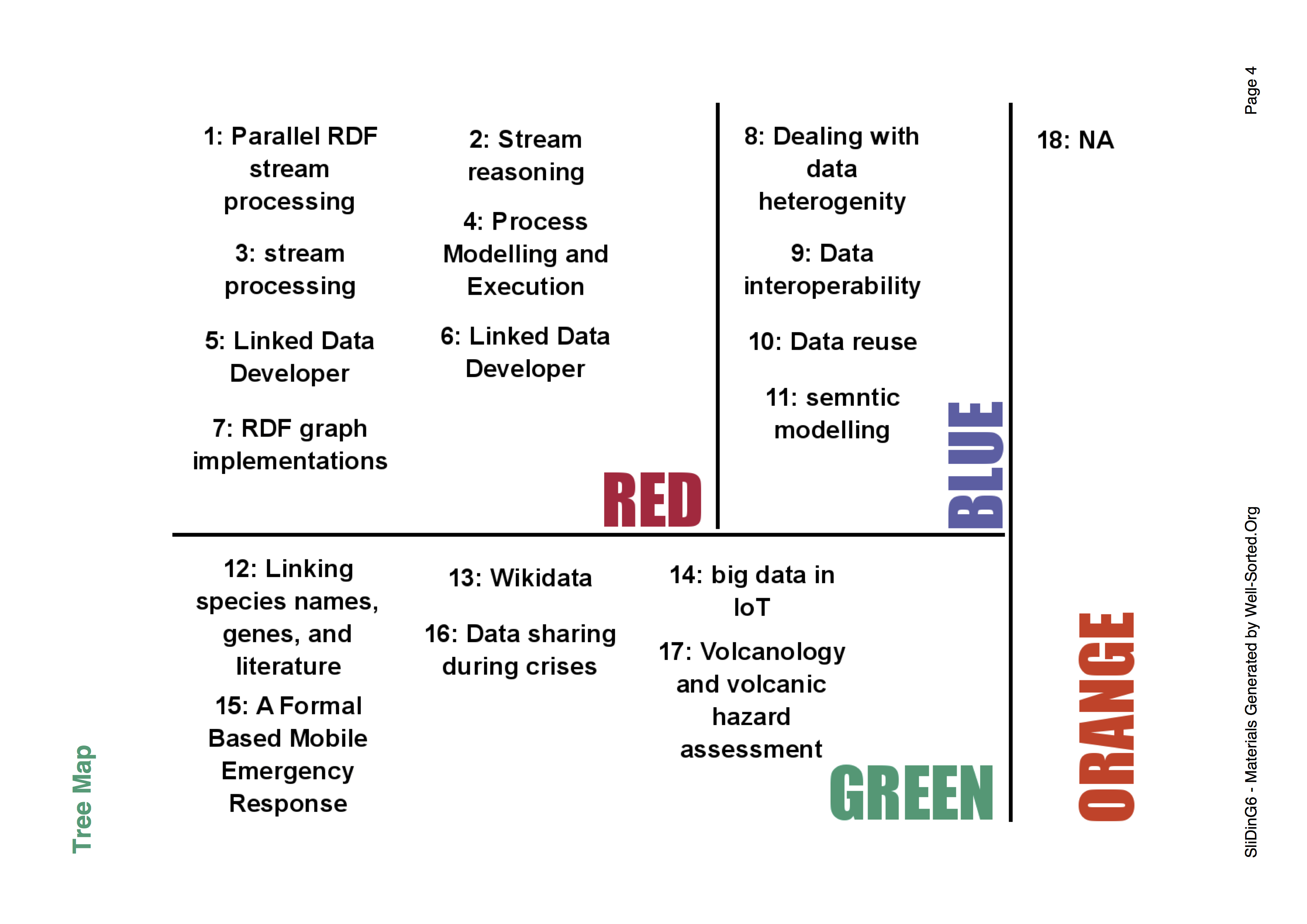
There was a great and vibrant workshop programme. My paper [3] was presented during the Enabling Open Semantic Science workshop (SemSci 2018) and resulted in a good deal of discussion. There were also great keynotes at the workshop from Paul Groth (slides) and Yolanda Gil which I would recommend anyone to look over.
I regret not having gone to more of the Industry Track sessions. The one I did make was very inspiring to see how the results of the community are being used in practice, and to get insights into the challenges faced.
The conference banquet involved a walking dinner around the Monterey Bay Aquarium. This was a great idea as it allowed plenty of opportunities for conversations with a wide range of conference participants; far more than your standard banquet.
Here are some other takes on the conference:
I also managed to sneak off to look for the sea otters.

[1]
![[doi]](http://www.macs.hw.ac.uk/~ajg33/wp-content/plugins/papercite/img/external.png)
Colin R. Batchelor, Christian Y. A. Brenninkmeijer, Christine Chichester, Mark Davies, Daniela Digles, Ian Dunlop, Chris T. A. Evelo, Anna Gaulton, Carole A. Goble, Alasdair J. G. Gray, Paul T. Groth, Lee Harland, Karen Karapetyan, Antonis Loizou, John P. Overington, Steve Pettifer, Jon Steele, Robert Stevens, Valery Tkachenko, Andra Waagmeester, Antony J. Williams, and Egon L. Willighagen. Scientific Lenses to Support Multiple Views over Linked Chemistry Data. In
The Semantic Web – ISWC 2014 – 13th International Semantic Web Conference, Riva del Garda, Italy, October 19-23, 2014. Proceedings, Part I, page 98–113, 2014.
[Bibtex]
@inproceedings{BatchelorBCDDDEGGGGHKLOPSSTWWW14,
abstract = {When are two entries about a small molecule in different datasets the same? If they have the same drug name, chemical structure, or some other criteria? The choice depends upon the application to which the data will be put. However, existing Linked Data approaches provide a single global view over the data with no way of varying the notion of equivalence to be applied.
In this paper, we present an approach to enable applications to choose the equivalence criteria to apply between datasets. Thus, supporting multiple dynamic views over the Linked Data. For chemical data, we show that multiple sets of links can be automatically generated according to different equivalence criteria and published with semantic descriptions capturing their context and interpretation. This approach has been applied within a large scale public-private data integration platform for drug discovery. To cater for different use cases, the platform allows the application of different lenses which vary the equivalence rules to be applied based on the context and interpretation of the links.},
author = {Colin R. Batchelor and
Christian Y. A. Brenninkmeijer and
Christine Chichester and
Mark Davies and
Daniela Digles and
Ian Dunlop and
Chris T. A. Evelo and
Anna Gaulton and
Carole A. Goble and
Alasdair J. G. Gray and
Paul T. Groth and
Lee Harland and
Karen Karapetyan and
Antonis Loizou and
John P. Overington and
Steve Pettifer and
Jon Steele and
Robert Stevens and
Valery Tkachenko and
Andra Waagmeester and
Antony J. Williams and
Egon L. Willighagen},
title = {Scientific Lenses to Support Multiple Views over Linked Chemistry
Data},
booktitle = {The Semantic Web - {ISWC} 2014 - 13th International Semantic Web Conference,
Riva del Garda, Italy, October 19-23, 2014. Proceedings, Part {I}},
pages = {98--113},
year = {2014},
url = {http://dx.doi.org/10.1007/978-3-319-11964-9_7},
doi = {10.1007/978-3-319-11964-9_7},
}
[2]
Alasdair J. G. Gray. Dataset Descriptions for Linked Data Systems.
IEEE Internet Computing, 18(4):66–69, 2014.
[Bibtex]
@article{Gray14,
abstract = {Linked data systems rely on the quality of, and linking between, their data sources. However, existing data is difficult to trace to its origin and provides no provenance for links. This article discusses the need for self-describing linked data.},
author = {Alasdair J. G. Gray},
title = {Dataset Descriptions for Linked Data Systems},
journal = {{IEEE} Internet Computing},
volume = {18},
number = {4},
pages = {66--69},
year = {2014},
url = {http://dx.doi.org/10.1109/MIC.2014.66},
doi = {10.1109/MIC.2014.66},
}
[3] Alasdair J. G. Grayg. Using a Jupyter Notebook to perform a reproducible scientific analysis over semantic web sources. In
Enabling Open Semantic Science, Monterey, California, USA, 2018. Executable version: https://mybinder.org/v2/gh/AlasdairGray/SemSci2018/master?filepath=SemSci2018%20Publication.ipynb
[Bibtex]
@InProceedings{Gray2018:jupyter:SemSci2018,
abstract = {In recent years there has been a reproducibility crisis in science. Computational notebooks, such as Jupyter, have been touted as one solution to this problem. However, when executing analyses over live SPARQL endpoints, we get different answers depending upon when the analysis in the notebook was executed. In this paper, we identify some of the issues discovered in trying to develop a reproducible analysis over a collection of biomedical data sources and suggest some best practice to overcome these issues.},
author = {Alasdair J G Grayg},
title = {Using a Jupyter Notebook to perform a reproducible scientific analysis over semantic web sources},
OPTcrossref = {},
OPTkey = {},
booktitle = {Enabling Open Semantic Science},
year = {2018},
OPTeditor = {},
OPTvolume = {},
OPTnumber = {},
OPTseries = {},
OPTpages = {},
month = oct,
address = {Monterey, California, USA},
OPTorganization = {},
OPTpublisher = {},
note = {Executable version: https://mybinder.org/v2/gh/AlasdairGray/SemSci2018/master?filepath=SemSci2018%20Publication.ipynb},
url = {http://ceur-ws.org/Vol-2184/paper-02/paper-02.html},
OPTannote = {}
}