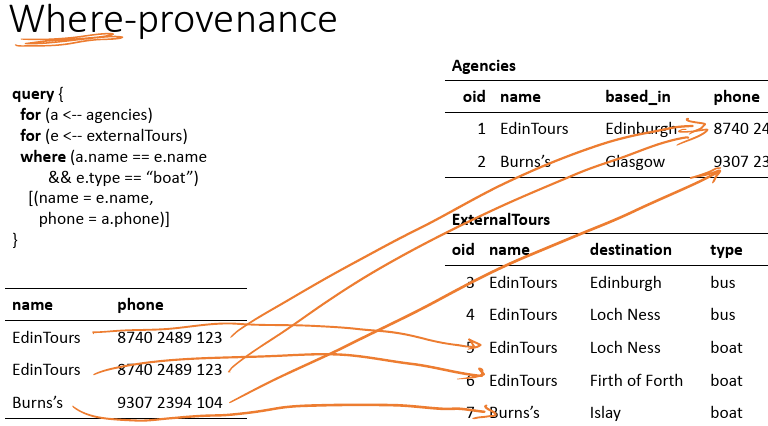
On 5 December 2016 I presented a tutorial [1] on the Heath Care and Life Sciences Community Profile (HCLS Datasets) at the 9th International Semantic Web Applications and Tools for the Life Sciences Conference (SWAT4LS 2016). Below you can find the slides I presented. The 61 metadata properties from 18 vocabularies reused in the HCLS Community […]
On 5 December 2016 I presented a tutorial [1] on the Heath Care and Life Sciences Community Profile (HCLS Datasets) at the 9th International Semantic Web Applications and Tools for the Life Sciences Conference (SWAT4LS 2016). Below you can find the slides I presented.
The 61 metadata properties from 18 vocabularies reused in the HCLS Community Profile are available in this spreadsheet (.ods).
[1] M. Dumontier, A. J. G. Gray, and S. M. Marshall, “Describing Datasets with the Health Care and Life Sciences Community Profile,” in
Semantic Web Applications and Tools for Life Sciences (SWAT4LS 2016), Amsterdam, The Netherlands, 2016.
[Bibtex]
@InProceedings{Gray2016SWAT4LSTutorial,
abstract = {Access to consistent, high-quality metadata is critical to finding, understanding, and reusing scientific data. However, while there are many relevant vocabularies for the annotation of a dataset, none sufficiently captures all the necessary metadata. This prevents uniform indexing and querying of dataset repositories. Towards providing a practical guide for producing a high quality description of biomedical datasets, the W3C Semantic Web for Health Care and the Life Sciences Interest Group (HCLSIG) identified Resource Description Framework (RDF) vocabularies that could be used to specify common metadata elements and their value sets. The resulting HCLS community profile covers elements of description, identification, attribution, versioning, provenance, and content summarization. The HCLS community profile reuses existing vocabularies, and is intended to meet key functional requirements including indexing, discovery, exchange, query, and retrieval of datasets, thereby enabling the publication of FAIR data. The resulting metadata profile is generic and could be used by other domains with an interest in providing machine readable descriptions of versioned datasets. The goal of this tutorial is to explain elements of the HCLS community profile and to enable users to craft and validate descriptions for datasets of interest.},
author = {Michel Dumontier and Alasdair J. G. Gray and M. Scott Marshall},
title = {Describing Datasets with the Health Care and Life Sciences Community Profile},
OPTcrossref = {},
OPTkey = {},
booktitle = {Semantic Web Applications and Tools for Life Sciences (SWAT4LS 2016)},
year = {2016},
OPTeditor = {},
OPTvolume = {},
OPTnumber = {},
OPTseries = {},
OPTpages = {},
month = dec,
address = {Amsterdam, The Netherlands},
OPTorganization = {},
OPTpublisher = {},
note = {(Tutorial)},
url = {http://www.swat4ls.org/workshops/amsterdam2016/tutorials/t2/},
OPTannote = {}
}