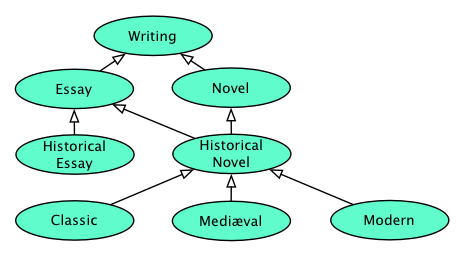
Figure 1: A Concept Hierarchy or Ontology
© 2005 James Bailey, François Bry, Tim Furche, and Sebastian Schaffert
The teaching material made available here is exclusively for private use and for use within REASE, the Repository of EASE for Learning Units. No part of it may be distributed in classes, or in publications, reproduced, stored in a retrieval system, or published, in any form or by means electronic, mechanical, photocopying, or otherwise, without prior written permission of the authors.
The Semantic Web aims at enriching Web data with meta-data and the processing of Web data with reasoning capabilities.
"The Semantic Web will bring structure to the meaningful content of Web pages, creating an environment where software agents roaming from page to page can readily carry out sophisticated tasks for users." [37].
"For the Semantic Web to function, computers must have access to structured collections of information and sets of inference rules that they can use to conduct automated reasoning." [37].
RDF [217], Topic Maps [155], OWL (formerly known as DAML-OIL) [23, 151] give rise to express relationships such as concept hierarchies or ontology, like that of the Figure 1, and application dependent relations between concepts.
Figure 1: A Concept Hierarchy or Ontology
Expressible in RDF and Topic Maps: "Book A is authored by person B."
RDFS [51] and OWL give rise to express: "No 'person' can be a 'text'."
Enabling requirement for the Semantic Web: Integrated access to both Semantic Web data (i.e. RDF, Topic Maps, and OWL data) and Web data (i.e. (X)HTML and XML data).
Access to (Semantic) Web data: Objective of (Semantic) Web query languages.
(Semantic) Web query languages range:
This presentation introduces into some of query languages proposed for the major representation formalisms of the (Semantic) Web: XML, RDF, and Topic Maps.
Query languages for OWL are not addressed in this presentation, because
The article "Web and Semantic Web Query Languages: A Survey" upon which this presentation is based introduces in more details in approximately 50 (Semantic) Web query languages.
This presentation does not aim to be a comprehensive tutorial for each of the languages it introduces into.
An XML documents consist of a document prologue and a document tree containing elements, character data and attributes, with a distinguished root element.
An element consists in an opening tag and a closing tag that enclose the element content.
An opening tag has the form
<label ...> and contains the
element's label or type and optionally a set of attributes. A
closing tag has the form
</label>, i.e. it contains only the
label.
The content of an element consists
of other elements, character data, or both (mixed content). An
element with label 'label' and without content, i.e. a so-called
empty element may be
abbreviated as <label/>.
XML documents have to be well-formed, i.e.
an interleaving of the opening and closing tags with different labels
(e.g. <b><i>Text</b></i>)
is forbidden.
The order of elements is significant. It induces the so-called document order.
Opening tags may contain key/value pairs of the form
name="value"
called attributes.
References of various kinds, especially ID/IDREF attributes and hypertext links, make possible to refer to an element instead of including it.
An XML document can be seen as a rooted, unranked, and ordered tree called document tree, if one does not consider the various referencing or linking mechanisms of XML. This interpretation is that of the data model of XML, of XPath and XQuery, and of most XML query languages. It is however too simplistic.
RDF data are sets of triples, or statements, (Subject, Property, Object). In RDF, all relations, called properties, are binary.
Nodes, i.e. subjects and objects, either
RDF data can be seen as a directed graph: Nodes are the statements' subjects and objects; arcs are the statements' properties. The URIs make graph traversals possible.
RDF data can be represented in XML or other textual formats in various manners, called serialisations.
Specific properties are predefined in the RDF and RDFS specifications [51, 148, 172, 194], e.g.:
rdf:type for specifying the type,
or class membership, of resources,
rdfs:subClassOf for specifying
class-subclass relationships between subjects/objects,
rdfs:subPropertyOf for specifying
property-subproperty relationships between properties.
rdfs:subClassOf and
rdfs:subPropertyOf are transitive and need not
be orders (or hierarchies). Inheritance in RDFS is peculiar:
rdfs:subClassOf relation,
rdfs:subClassOf relation
can be cyclic,
RDFS has meta-classes, e.g.
rdfs:Class,
the class of all classes, and rdfs:Property,
the class of all properties.
RDF allows one to define instances; RDFS allows one to define RDF Schemas or ontologies.
The main concepts of Topic Maps are topics, associations, and occurrences.
Topics might have types, what expresses memberships in classes, that are topics as well, called topic types. A topic can have one or more names.
Associations are n-ary relations (with n ≥ 2) between topics. Associations might have role and roles types.
Occurences are "information resources relevant to a topic", i.e. instances of a class. An occurrence might have one or several types characterising its "relevance to a topic", i.e. memberships into classes.
The types, i.e. classes, of an occurence are expressed by
Like RDF data, Topic Map data, short topic maps, can be seen as oriented graphs with labeled nodes and edges.
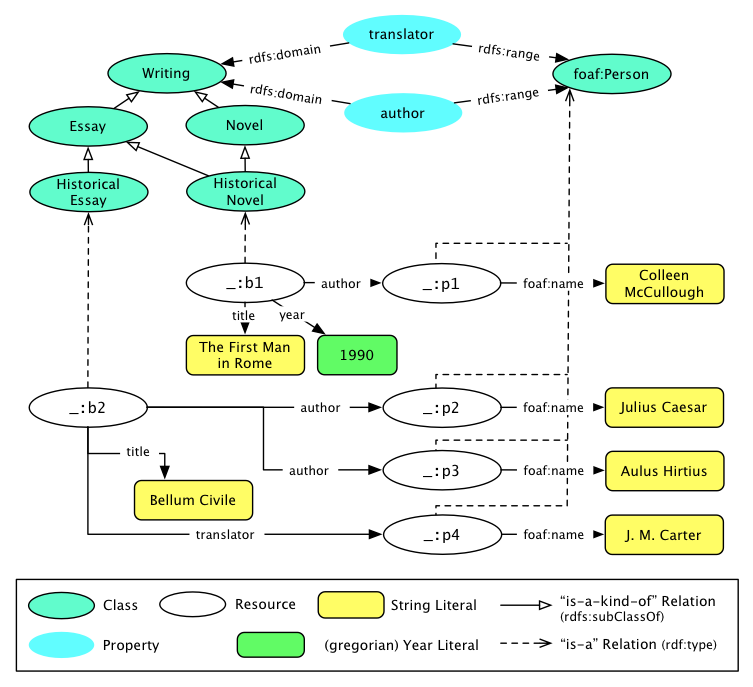
Figure 2: Sample data as a (simplified) RDF graph
Figure 2 gives an ontology with the book categories Writing, Novel, Essay, Historical Novel, and Historical Essay.
Figure 2 also gives two instances, the books The First Man in Rome (a Historical Novel authored by Colleen McCullough) and Bellum Civile (a Historical Essay authored by Julius Caesar and Aulus Hirtius, and translated by J.M. Carter).
Historical Novel is both, a Novel and an Essay.
A book may optionally have a translator, as is the case of Bellum Civile.
The RDF representation of the book recommender is given here in the Turtle serialisation [24].
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> .
@prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#> .
@prefix xsd: <http://www.w3.org/2001/XMLSchema#> .
@prefix foaf: <http://xmlns.org/foaf/0.1/> .
:Writing a rdfs:Class ;
rdfs:label "Writing" .
:Novel a rdfs:Class ;
rdfs:label "Novel" ;
rdfs:subClassOf :Writing .
:Essay a rdfs:Class ;
rdfs:label "Essay" ;
rdfs:subClassOf :Writing .
:Historical_Essay a rdfs:Class ;
rdfs:label "Historical Essay" ;
rdfs:subClassOf :Essay .
:Historical_Novel a rdfs:Class ;
rdfs:label "Historical Novel" ;
rdfs:subClassOf :Novel ;
rdfs:subClassOf :Essay .
:author a rdfs:Property ;
rdfs:domain :Writing ;
rdfs:range foaf:Person .
:translator a rdfs:Property ;
rdfs:domain :Writing ;
rdfs:range foaf:Person .
_:b1 a :Historical_Novel ;
:title "The First Man in Rome" ;
:year "1990"^^xsd:gYear ;
:author [foaf:name "Colleen McCullough"] .
_:b2 a :Historical_Essay ;
:title "Bellum Civile" ;
:author [foaf:name "Julius Caesar"] ;
:author [foaf:name "Aulus Hirtius"] ;
:translator [foaf:name "J. M. Carter"] .
Books, authors, and translators are represented by blank nodes (without identifiers), or with temporary identifiers (prefix "_:")
The Topic Map representation of the book recommender is in the Linear Topic Maps syntax [125].
/* Association and topic types for subclass-superclass hierarchy */
[superclass-subclass = "Superclass-Subclass Association Type"
@ "http://www.topicmaps.org/xtm/1.0/core.xtm#superclass-subclass" ]
[superclass = "Superclass Role Type"
@ "http://www.topicmaps.org/xtm/1.0/core.xtm#superclass" ]
[subclass = "Subclass Role Type"
@ "http://www.topicmaps.org/xtm/1.0/core.xtm#subclass" ]
/* Topic types */
[Writing = "Writing Topic Type" @ "http://example.org/books#Writing" ]
[Novel = "Novel Topic Type" @ "http://example.org/books#Novel" ]
[Essay = "Essay Topic Type" @ "http://example.org/books#Essay" ]
[Historical_Essay = "Historical Essay Topic Type"
@ "http://example.org/books#Historical_Essay" ]
[Historical_Novel = "Historical Novel Topic Type"
@ "http://example.org/books#Historical_Novel" ]
[year = "Topic Type for a Gregorian year following ISO 8601"
@ "http://www.w3.org/2001/XMLSchema#gYear" ]
[Person = "Person Topic Type" @ "http://xmlns.org/foaf/0.1/Person"]
[Author @ "http://example.org/books#author" ]
[Translator @ "http://example.org/books#translator" ]
/* Associations among the topic types */
superclass-subclass(Writing: superclass, Novel: subclass)
superclass-subclass(Writing: superclass, Essay: subclass)
superclass-subclass(Novel: superclass, Historical_Novel: subclass)
superclass-subclass(Essay: superclass, Historical_Essay: subclass)
superclass-subclass(Essay: superclass, Historical_Novel: subclass)
superclass-subclass(Person: superclass, Author: subclass)
superclass-subclass(Person: superclass, Translator: subclass)
/* Occurrence types */
[title = "Occurrence Type for Titles" @ "http://example.org/books#title" ]
/* Association types */
[author-for-book = "Association Type associating authors to books"]
[translator-for-book =
"Association Type associating translators to books"]
[publication-year-for-book =
"Association Type associating translators to books"]
/* Topics, associations, and occurrences */
[p1: Person = "Colleen McCullough"]
[p2: Person = "Julius Caesar"]
[p3: Person = "Aulus Hirtius"]
[p4: Person = "J. M. Carter"]
[b1: Historical_Essay = "Topic representing the book 'First Man in Rome'"]
author-for-book(b1, p1: author)
publication-year-for-book(b1, y1990)
{b1, title, [[The First Man in Rome]]}
[b2: Historical_Novel = "Topic representing the book 'Bellum Civile'"]
author-for-book(b2, p2: author)
author-for-book(b2, p3: author)
translator-for-book(b2, p4: translator)
{b2, title, [[Bellum Civile]]}
Subclass-superclass associations are identified using the subject identifiers of XTM [232].
For illustration purposes, the title of a book is represented as an occurrence of that book/topic.
<bookdata xmlns:xsd="http://www.w3.org/2001/XMLSchema#">
<book type="Historical_Novel">
<title>The First Man in Rome</title>
<year type="xsd:gYear">1990</year>
<author> <name>Colleen McCullough</name> </author>
</book>
<book type="Historical_Essay">
<title>Bellum Civile</title>
<author> <name>Julius Caesar</name> </author>
<author> <name>Aulus Hirtius</name> </author>
<translator> <name>J. M. Carter</name> </translator>
</book>
<category id="Writing">
<label>Writing</label>
<category id="Novel">
<label>Novel</label>
<category id="Historical_Novel">
<label>Historical Novel</label>
</category>
</category>
<category id="Essay">
<label>Essay</label>
<category id="Historical_Essay">
<label>Historical Essay</label>
</category>
<category idref="Historical_Novel" />
</category>
</category>
</bookdata>
For the sake of brevity, the above representation does not express that authors and translators are persons.
Note the use of ID/IDREF references for expressing the book types (e.g. "Novel", "Historical_Novel").
"Selection queries" illustrates the format of answers and how related information can be selected and delivered:
Query 1: "Select all Essays together with their authors (i.e. author items and corresponding names)."
"Extraction queries" extract substructures from data graphs or tree:
Query 2: "Select all data items with any relation to the book titled 'Bellum Civile'."
"Reduction queries" sprecify what parts of the data not to include in the answer:
Query 3: "Select all data items except ontology information and translators."
It is often desirable to restructure data, possibly into different formats or different serialisations:
Query 4: "Invert the relation author (from a book to an author) into a relation authored (from an author to a book)."
RDF requires restructuring in particular for reification, which in turn is needed in RDF for making statements on statements. For example, the statement
S: "Julius Caesar is author of Bellum Civile"
is reified by the following three statements:
One distinguishes between value
aggregation like SQL's max(·),
sum(·), ... and structural
aggregation like
"how many nodes?". Query 5 uses value
aggregation, Query 6 uses structural aggregation:
Query 5: "Return the last year in which an author with name 'Julius Caesar' published something."
Query 6: "Return each of the subclasses of 'Writing', together with the average number of authors per publication of that subclass."
Related to aggregation are grouping and sorting.
It is often necessary to combine information that is not explicitly connected:
Query 7:
"Combine the information about the book
titled 'The Civil War' and authored by 'Julius Caesar'
with the information about the book with identifier
'bellum_civile'."
Combination queries are related to inference, e.g.:
"If the books entitled 'Bellum Civile' and 'The Civil War' are the same book, and if 'Julius Caesar' is an author of 'Bellum Civile', then 'Julius Caesar' is also an author of 'The Civil War' ".
Query 8:
"Return the transitive closure of the
subClassOf relation."
Not all inference queries are combination queries:
Query 9: "Return the co-author relationship between two persons that stand in author relationships with the same book."
Most query and transformation languages for XML specify the structure of the XML data to retrieve using one of:
Language already standardized, or currently in the process of standardisation by the W3C are navigational.
Many research languages are positional.
This presentation does not consider:

Figure 3: History of the XML Query Languages
The navigational languages for XML are inspired from path-based query languages designed for (relational or object-oriented) databases.
Such database query languages (e.g., GEM [286], an extension of QUEL, and OQL [73]) require fully specified paths, i.e., paths with explicitly named nodes following only parent-child connections.
OQL expresses paths with the extended dot notation introduced with GEM [286]:
SELECT b.translator.name FROM Books b
selects the name, or component, of the translator of books. There must be at most one translator per book for this expression to be legal.
Generalized (or regular) path expressions [83, 119], allow more powerful constructs, e.g., the Kleene closure operator, *.
As a consequence, generalized path expressions do not require explicit naming of all nodes along a path.
Lorel [3] is an early proposal for semistructured data, a data model introduced with the Object Exchange Model (OEM) [127, 230] and a precursor of XML.
Lorel's syntax resembles that of SQL and OQL, extending OQL's extended dot notation to generalized path expressions. Lorel provides a means for expressing:
SELECT b.translator.name FROM Books b
b.author.name
Query 1 ("Select all Essays together with their authors, i.e. author items and corresponding names.") against the XML sample data in Lorel (attributes are treated as sub-elements since OEM has no attributes):
select xml(results:(
select xml(result:(
select B, B.author
from bookdata.book B
where B.type = bookdata.(category.id)+
) ) ) )
Lines 1 and 2 are constructors wrapping the selected books and their authors into XML elements.
Assume that
Books having 'Julius Caesar' either as author or translator can be selected in Lorel by adding the following expression to the query after line 5:
B.(author|translator).name? = "Julius Caesar".
XPath [86, 258, 269] has been defined as part of XSL, a stylesheet language for XML (defined in replacement of SGML's stylesheet language DSSSL).
XPath provides expressions inspired from file systems for selecting data in terms of a navigation through an XML document.
XPath's Data Model: An XML document is seen
as an ordered tree with nodes for elements, attributes, character data,
namespaces declaration, comments and processing instructions.
The root of this tree is a special node which
has the node for the XML document element as (single) child.
Nodes for character data, for comments, and for processing instructions
are children of the node of the element in which they occur, or of
the root node if they are outside the document element.
A character node is always maximal, ie., it
is not allowed that two character data nodes are immediate siblings
This model resembles the XML Information Set
recommendation [94] and has become the
foundation for most activities of the W3C related to query languages.
XPath expressions: The core expressions location steps specifying where to navigate from the context node. A location step consists of three parts: an axis, a node-test, and an optional predicate.
Base Axes:
self
child
following-sibling
following
Transitive and
Transitive-Reflexive Closure Axes
of the base axis child:
descendant
descendant-or-self
Reverse Axes of the preceding axes:
parent
preceding-sibling
preceding
ancestor
ancestor-or-self
Additional Axes:
attributes
namespace
Node-tests and predicates restrict the nodes selected by an axis. They either restrict the label of the node (in case of element and attribute nodes), or the type of the node (e.g., restrict to comment children of an element).
Predicates restrict elements to some neighborhood or using functions (e.g., arithmetic or boolean operators).
Successive location steps are separated by "/" .
The XPath expression
child::book/descendant::name
expresses: "For each book child of the context
node, select its name descendants".
Comparison of XPath and Generalized Path Expressions (cf. supra 3.1.2):
It has been shown in [225] that reverse axes do not increase the expressive power of path navigations.
Without closure of arbitrary path expressions, XPath cannot express regular path expressions such as [199, 200]:
a.(b.c)*.d
meaning select d's that are reached via one
a and then arbitrary many repetitions of one
b followed by one c and
a.b*.c
Query 1 ("Select all Essays together with their authors, i.e. author items and corresponding names.") against the XML sample data can in XPath only be approximated as follows:
/descendant::book[attribute::type =
/descendant::category[attribute::id = "Essay"]/
descendant-or-self::category/attribute::id]
XPath always returns a single set of nodes and provides no construction. Therefore, it is not possible to return authors and their names together with the book.
The above XPath query can be expressed using XPath's abbreviated syntax:
//book[//category[//category[@::id = "Essay"]/
descendant-or-self::category/@id]
Query 2 ("Select all data items with any relation to the book titled 'Bellum Civile'.") can be expressed in (abbreviated) XPath as:
//book[title="Bellum Civile"]
XPath returns a set of nodes as result of a query, the serialization being left to the host language. Most host languages consider as results the sub-trees rooted at the selected nodes, as desired by this query. The link to the category is not expressed by means of the XML hierarchy and therefore not included in the result.
Query 3 ("Select all data items except ontology information and translators.") can be approximated in XPath (assuming 'ontology information' is identified with 'category elements'):
/bookdata//*[name(.) != "translator" and name(.) != "category"]
This query returns all descendants of the document element
bookdata the labels of which (returned by the XPath function
name) are neither translator nor category.
While this seems a convenient solution for Query 3 (the
set of nodes returned by the expression indeed does not contain
translators and categories), the link between selected book
nodes
and the excluded translators is not removed. In most host
languages translators would be included as part of
their book parent.
Queries 4 and 7-9 cannot be expressed in XPath because they require some form of construction.
Aggregations, needed by Query 5, are provided by XPath. Query 5 ("Return the last year in which an author with name 'Julius Caesar' published something.") can be expressed as follows:
max(//book[author/name="Julius Caesar"]/year)
The aggregation in Query 6 can be expressed analogously. However, Query 6 like Query 1 cannot be expressed in XPath properly due to the lack of construction.
XPathLog [203] is syntactically an extension of XPath.
XPathLog's semantics and evaluation are based on logic programming, more specifically F-Logic and FLORID [188].
XPathLog extends the syntax of XPath as follows:
//book[name ! N] ! B
B to books and N
to the names of the books.
The data model of XPathLog deviates considerably from XPath's data model: XML documents are viewed in XPathLog as edge-labeled graphs with implicit dereferencing of ID/IDREF references.
XPathLog provides means for constructing new data and for updating existing data, as well as more advanced reactive features for processing integrity constraints.
XSLT [85], the Extensible Stylesheet Language, has been conceived for transforming XML documents.
The distinction between querying and transformation has become increasingly blurred with the increase in expressiveness of query and transformation languages.
XSLT uses an XML syntax with embedded XPath expressions.
An XSLT program, called stylesheet is composed of one or more transformation rules called templates.
Templates recursively operate on a single input document.
A template specifies:
XSLT allows also recursive templates but recursion is limited: Except for templates constructing strings only, the result of a template is immutable (a so-called result tree fragment) and, except for literal copies, cannot be input for further templates.
As a consequence, no views can be defined in XSLT.
Thanks to its string processing capabilities, XSLT is Turing complete [169].
XSLT 2.0 [167] aims at overcoming limitations of XSLT (e.g. single input document, restricted recursion, no support for XML Schema, limited support for namespaces, lack of specific grouping constructs)
All sample queries can be expressed in XSLT.
Query 1 ("Select all Essays together with their authors, i.e. author items and corresponding names.") can be expressed in XSLT as follows:
<xsl:stylesheet version="1.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:template match="/">
<results>
<xsl:apply-templates select="//book[@type =
//category[@id = 'Essay']/descendant-or-self::category/@id]"/>
</results>
</xsl:template>
<xsl:template match="book">
<result>
<xsl:copy select = "."/>
<xsl:apply-templates select="author|author/name" />
</result>
</xsl:template>
<xsl:template match="author|author/name">
<xsl:copy-of select="." />
</xsl:template>
</xsl:stylesheet>
This stylesheet can be evaluated as follows:
<results> element and within it
try to recursively apply the templates to all nodes matched
by the XPath expression in the select attribute of the
apply-templates statement in line 5.
book elements matched by the second
template which creates a <result> element,
makes a shallow copy of itself and recursively applies the
rules to the bookN's author children and their
name children.
author or name of an
author, copy the complete input to the result.
Query 2 and 5 to 8 are omitted as their implementations in XSLT are similar to that of other queries.
Aside from templates, XSLT also provides
explicit iteration,
selection, and
assignment:
xsl:for-each, xsl:if,
xsl:variable among others.
Using these constructs one can also formulate
Query 1
("Select all Essays together with
their authors, i.e. author items and corresponding
names.")
as follows:
<results xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:for-each select="//book[@type = //category[@id = 'Essay']/
descendant-or-self::category/@id]">
<result>
<xsl:copy select = "."/>
<xsl:for-each select = "author|author/name">
<xsl:copy-of select="." />
</xsl:for-each>
</result>
</xsl:for-each>
</results>
The xsl:for-each expressions iterate over the
elements selected by the XPath expression in their select
attribute. Aside from the expressions for copying input, this
realisation of Query 1 in XSLT closely resembles its
implementation in XQuery given in the following section.
The programming style of the first implementation of Query 1 is often called rule-based, that of the second implementation of Query 1, "fill-in-the-blanks".
Query 3 ("Select all data items except ontology information and translators.") can be expressed in XSLT as follows:
<xsl:stylesheet version="1.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:template match="@*|node()">
<xsl:copy>
<xsl:apply-templates select="@*|node()"/>
</xsl:copy>
</xsl:template>
<xsl:template match="translator | category" />
</xsl:stylesheet>
The first template specifies that for all attributes and nodes, the node itself is copied and their (attribute and node) children are processed recursively.
The second template specifies that for translators and category elements, nothing is generated (and their children are not processed).
The first template also matches translator and category elements. For such a case where multiple templates match, XSLT uses detailed conflict resolution policies [85]: The second template is chosen as it is more specific than the first one.
Query 4 ("Invert the relation author (from a book to an author) into a relation authored (from an author to a book).") can be expressed in XSLT as follows:
<xsl:stylesheet version="1.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:template match="/">
<bookdata>
<xsl:apply-template
select="//author[not(name = preceding::author/name)]" />
</bookdata>
</xsl:template>
<xsl:template match="author">
<person>
<name><xsl:value-of select="name" /></name>
<authored>
<xsl:apply-templates
select="//book[author/name=current()/name]" />
</authored>
</person>
</xsl:template>
<xsl:template match="book">
<book>
<xsl:copy-of select="@*" />
<xsl:copy-of select="*[name() != 'author']" />
</book>
</xsl:template>
</xsl:stylesheet>
The preceding axis from XPath is used to avoid
duplicates in the result. The function current()
(in the second template) returns the current node, here,
the author element last matched by the second
template.
(This function is essentially syntactic sugar to limit the use
of variables, cf. implementation of Query 9).
Query 9 ("Return the co-author relationship between two persons that stand in author relationships with the same book.") can be expressed in XSLT as follows:
<xsl:stylesheet version="1.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:template match="/">
<results>
<xsl:for-each select="//author">
<xsl:variable name="author" select="." />
<xsl:for-each select="$author/following-sibling::author">
<co-authors>
<name> <xsl:value-of select="$author/name" /> </name>
<name> <xsl:value-of select="current()/name" /> </name>
</co-authors>
</xsl:for-each>
</xsl:for-each>
</results>
</xsl:template>
</xsl:stylesheet>
This implementation of Query 9 in XSLT is very similar of the implementation of Query 9 in XQuery given below.
The implementation of Query 9 given above uses xsl:for-each,
as the inner and the outer author are processed differently.
A solution without xsl:for-each is possible but requires
parameterized templates and named or grouped templates:
<xsl:stylesheet version="1.0"
xmlns:xsl="http://www.w3.org/1999/XSL/Transform">
<xsl:template match="/">
<results>
<xsl:apply-template select="//author" />
</results>
</xsl:template>
<xsl:template match="author">
<xsl:apply-template select="following-sibling::author"
mode="co-author">
<xsl:with-param name="first-co-author" select="." />
</xsl:apply-templates>
</xsl:template>
<xsl:template match="author" mode="co-author">
<xsl:param name="first-co-author" />
<co-authors>
<name> <xsl:value-of select="$first-co-author/name" /> </name>
<name> <xsl:value-of select="name" /> </name>
</co-authors>
</xsl:template>
</xsl:stylesheet>
For simplicity, none of the two implementations of Query 9 given above eliminate duplicates (occurring if if two persons are co-authors of several books).
An activity towards specifying an XML query language, now XQuery, has been launched by W3C shortly before the publication of the final XPath 1.0 and XSLT 1.0 recommendations.
Requirements and use cases have been given in [76, 77, 192]. Proposals, e.g., XQL and Quilt, have been made that have influenced XQuery [42]:
XQuery's developement is not completed. It represents the state-of-the-art of navigational XML query languages.
XQuery Principles: XQuery is an extension of XPath 2.0 adding:
for clauses, an optional
where clause, an optional
order by, and a return
clause.
in part:
for $book in //book
books selected by the path expression
//book.
where clause
specifies conditions on the selected
data items.
order by clause allows
the items to be
processed in a certain order.
return clause specifies
the result of the entire FLWOR expression (often using
constructors as shown above).
for clauses,
let clauses that also
bind variables but without iterating over the individual data
items in the sequence bound to the variable.
unordered keyword indicating that the
order of elements in
sequences that are constructed or returned as result of
XQuery expressions is not relevant. E.g.,
unordered{for $book in //book return $book/name}
//book may be processed in any order in the
for
clause and the order of the resulting name nodes also can be
arbitrary (i.e. implementation dependent). Within
unordered query parts, the result of expressions querying
the order of elements in sequences such as fn:position or
fn:last is non-deterministic.
validate expression.
Not all of XPath's axes are mandatory in XQuery implementations:
ancestor, ancestor-or-self, following,
following-sibling, preceding, and
preceding-sibling do not have to be supported.
This is no restriction to XQuery's expressiveness, as expressions using
reverse axes can be rewritten [225], and the
"horizontal axes", e.g., following and
following-sibling, can be replaced by FLWOR expressions using the
<< and >> operators that compare two nodes with
respect to their position in a sequence.
Sample Queries: All nine sample queries can be expressed in XQuery. Query 2 is omitted because it can be expressed as a simplification of of Query 1. Query 5 can be expressed in XPath. Query 8 and 9 are similar. Sincve Query 9 in XQuery exhibits an interesting anomaly, it is given below and Query 8 is not given.
Query 1 ("Select all Essays together with their authors, i.e. author items and corresponding names.") can be expressed in XQuery as follows (interpreting the phrase an essay as a book with type attribute equal to the id of the category Essay or one of its sub-categories represented as descendants in the XML structure):
<results> {
let $doc := doc("http://example.org/books")/bookdata
let $sub-of-essay :=
$doc//category[@id="Essay"]/descendant-or-self::category
for $book in $doc//book
where $book/@type = $sub-of-essay/@id
return
<result>
{ $book }
{ $book/author }
{ $book/author/name }
</result> }
</results>
Note the use of the let clause in line 2: the sequence of all
sub-categories of the category with id Essay
including that category itself (we use the reflexive transitive axis
descendant-or-self) is bound to the variable. However,
in contrast to a for expression, this
sequence is not iterated over. Instead of the
where clause in line 4 a predicate could be
added to the path expression in line 3 resulting in the expression
$doc//book[@type = $sub-of-essay/@id].
Query 3 ("Select
all data items except ontology information and
translators.") requires
structural recursion while constructing
new elements that are identical to the
ones encountered, except omitting translator and category
nodes. The following implementation shows the use of a
user-defined, recursive function that copies the tree rooted at
its first parameter $e, except all nodes in the sequence given
as second parameter.
declare function
local:tree-except($e as element(),
$exceptions as node()*) as element()*
{
element {fn:node-name($e)} {
$e/@* except $exceptions, (: copy the attributes :)
for $child in $element/node() except $exceptions
return
if $child instance of element()
(: for elements process them recursively :)
local:tree-except($section)
else (: others (text, comments, etc. copy :)
$child
}
};
document {
let $doc := doc("http://example.org/books")/bookdata
let $exceptions := $doc//translator union $doc//category
local:tree-except($doc, $exceptions)
}
Note the typing of the parameters: the first parameter is a single element, the second, a sequence of nodes and the function returns a sequence of elements. In the main part of the query, the document constructor is used to indicate that its content is to be the document element of the constructed tree.
Query 4 ("Invert the relation author (from a book to an author) into a relation authored (from an author to a book).")
<bookdata> {
let $a := doc("http://example.org/books")//author
for $name in distinct-values($a/name)
return
<person>
<name> { $name } </name>
<authored
{
for $b in doc("http://example.org/books")//book
where some $ba in $b/author
satisfies $ba/name = $name
return
<book> { $b/@*, $b/* except $b/author } </book>
}
</authored
</person>
}
</bookdata>
This implementation is in fact similar to the implementation of use case XMP-Q4 in [76]. It exhibits two noteworthy functionalities:
distinct-value in line 3 to avoid duplication
in the result, if an author occurs several times in
the document.
books where some (i.e. at least one) of the
authors have the same name as the
currently considered author.
Using aggregation expressions (see lines 8 and 10), Query 6 ("Return each of the subclasses of 'Writing', together with the average number of authors per publication of that subclass.") can be expressed in XQuery as follows:
<results> {
let $doc := doc("http://example.org/books")/bookdata
for $category in $doc//category[@id="Essay"]//category
return
<category>
{ $category/@id }
<average-number-of-authors>{
fn:avg(for $book in $doc//book
where @type = $category/@id
return fn:count($book/author))
}
</average-number-of-authors>
</category>
}
</results>
Combining data can be expressed in a very compact manner in
XQuery, as the following expression of
Query 7
("Combine the information about the
book titled 'The Civil War' and authored by 'Julius Caesar'
with the information about the book with identifier
'bellum_civile'.")
shows:
<book>
{ for $book in doc("http://example.org/books")//book
where title="Bellum Civile" and author/name="Julius Caesar"
return ($book/@*, $book/*)
}
{
for $book in doc("http://example.org/books")//book
where @id="bellum_civile"
return ($book/@*, $book/*)
}
</book>
Query 9 ("Return the co-author relationship between two persons that stand in author relationships with the same book.") can be expressed in XQuery as follows:
<results>
{ let $doc := doc("http://example.org/books")
for $book in doc("http://example.org/books")//book
for $author in $book/author
for $co-author in $book/author
where $author << $co-author
return
<co-authors>
<name> { $author/name } </name>
<name> { $co-author/name } </name>
</co-authors>
}
</results>
This implementation does not treat the case where two authors
co-authored multiple books. In this case, duplicates are created
by the above solution. To avoid this the following refinement
uses the before operator << in combination with a negated
condition, for specifying that only such pairs of authors should
be considered, where there is no book that occurs prior to the
currently considered one and which is also co-authored by the
current pair of authors:
<results>
{ let $doc := doc("http://example.org/books")
for $book in doc("http://example.org/books")//book
for $author in $book/author
for $co-author in $book/author
where $author << $co-author and not(
some $pb in doc("http://example.org/books")//book
satisfies ($pb << $book and
$pb//author/name = $author/name and
$pb//author/name = $co-author/name))
return
<co-authors>
<name> { $author/name } </name>
<name> { $co-author/name } </name>
</co-authors>
}
</results>
It is intuitively clear that XQuery is Turing complete since it provides recursive functions and conditional expressions. A proof of the Turing-completeness of XQuery is given in [169].
The positional approach consists in using patterns to specify the position of data within larger structures.
Positional queries mimic the data to be queried. Languages using this query-by-example style for queries mostly fall into two categories:
UnQL [64, 66], the Unstructured Query Language, has been originally developed for querying semistructured data and nested relational databases with cyclic structures. UnQL has later been adapted to querying XML, but the origins are still apparent. For example, UnQL has a non-XML syntax very similar to OEM's syntax and does not support querying or construction of ordered data.
The evaluation model and core language of UnQL is based upon structural recursion over labeled trees.
The following expression uses functional style pattern matching for selecting all books in a tree.
fun f1(T1 ∪ T2) = f1(T1) ∪ f1(T2)
| f1({ L => T }) = if L = book
then {result => book => T}
else f1(T)
| f1({}) = {}
| f1(V) = {}
UnQL's surface syntax uses
query patterns
and construction patterns: a query
consists of a single select ... where ...
or traverse rule that separate
construction from querying.
Queries may be nested, in which case the separation of querying and construction is abandoned.
Query 1 ("Select all Essays together with their authors, i.e. author items and corresponding names.") can be expressed in UnQL as:
select { results => {
select { result => { Book,
select { author => {
author => Author,
authorName => Name
} }
where { author => \Author } ← Book,
{ name => \Name } ← Author
where { book => \Book } ← Bib
where bookdata => Bib ← DB
A ← scopes a query pattern, i.e. it specifies that the left-hand query pattern is to be found in bindings for the right-hand variable.
The => operator is the direct edge traversal operator. E.g.
book => author
specifies that author is a direct child of
book.
Recursive traversals can be specified using regular path expressions including regular expressions over labels. E.g.
_*
traverses over arbitrary many elements with any label,
[^book]**
over arbitrary many elements with any label except book.
UnQL also provides traverse clauses for reduction and restructuring queries like Query 3 ("Select all data items except ontology information and translators."):
traverse DB given X
case translator => _ then X := {}
case category => _ then X := {}
case \L => _ then X := {l => X}
This query is evaluated by traversing the tree in the database and matching recursively each element against the three case expressions. All elements except translators and categories are copied to the newly constructed tree, structured as in the input data.
UnQL s evaluation is founded in graph simulation [66].
[64] shows that all queries expressible in UnQL can be evaluated in PTIME.
XML-QL [98, 99] is a pattern-based and rule-based query language for XML developed specifically to address the W3C's call for an XML query language (that resulted in the development of XQuery).
Like UnQL, XML-QL uses query patterns called
element patterns in [98]
in a WHERE clause.
Such patterns can be augmented by variables for selecting data.
The result of a query is specified as a
construction pattern in the
CONSTRUCT clause.
An XML-QL query always consists of a single
WHERE-CONSTRUCT rule which may be divided
into several nested subqueries.
Query 1 ("Select all Essays together with their authors, i.e. author items and corresponding names.") can be expressed in XML-QL as follows:
WHERE
<bookdata>
<book>
</> ELEMENT_AS $b
</>
CONSTRUCT
<results>
<result>
$b
WHERE <author>
<name> $n </>
</> ELEMENT_AS $a
CONSTRUCT $a
$n
</>
</>
Variables are preceded in XML-QL by
$. Note how the grouping
of authors with their books is expressed
using a
nested query.
Also note the tag minimization (end tags
abbreviated by </> as in SGML).
In line 4, the variable $b is restricted to data
matching the pattern in
lines 3 and 4. Such pattern restrictions are indicated in XML-QL
using the ELEMENT AS keyword.
A characteristics of XML-QL is that it uses query patterns containing several variables that may select several data items at a time instead of path selections that may only select one data item at a time.
XML-QL's variables are similar to the variables of logic programming, i.e. "joins" can be expressed by variable name equality.
Since XML-QL does not allow one to use more than one rule, one often has to employ nested subqueries to express complex queries.
Query 6 ("Return each of the subclasses of 'Writing', together with the average number of authors per publication of that subclass.") cannot be expressed in XML-QL due to lack of aggregation, in particular structural aggregation (e.g., counting the number of children of an element).
The following query returns all books classified in a sub-category of Novel:
WHERE
<book type=$Sub>
</> ELEMENT_AS $b,
<category id='Novel'>
<category* id=$Sub>
</>
</>
CONSTRUCT $b
Joins are expressed by repeated occurrences of the same variable (lines 2 and 5). In line 5 a further feature of XML-QL is shown: regular path expressions for element labels in patterns.
Transformation queries such as Query 2, except for rather local changes (e.g., omission of elements or changing labels), cannot be expressed in XML-QL.
XML-QL has no means for testing the non-existence of elements and therefore cannot express queries such as "Return all books that have no translator.".
No results on the complexity or expressiveness of XML-QL have been published.
XMAS [189], the XML Matching And Structuring language, is an XML query language developed as part of MIX [18] and builds upon XML-QL.
Like XML-QL, XMAS uses query patterns,
construction patterns, and
rules of
the form CONSTRUCT ... WHERE ....
XMAS extends XML-QL in that it provides a powerful grouping construct, instead of relying on subqueries for grouping data items within an element.
Query 1 ("Select all Essays together with their authors, i.e. author items and corresponding names.") can be expressed in XMAS as follows:
WHERE
<bookdata>
$B: <book>
$A: <author>
<name> $N </name>
</>
</>
</>
CONSTRUCT
<results>
<result>
$B
<book-author>
$A
<name> $N </name>
</> {$A,$N}
</> {$B}
</>
Here, one can observe the two main syntactic differences to XML-QL:
result element is
created for every instance of $B (indicated by
{$B} after the closing tag of the element
result). Within every such result
element, all authors of a
book (indicated by {$A}) are collected nested in
book-author elements (the book-author
element is necessary because grouped variables are allowed only
after closing tags or single variables in XMAS).
$B in front of the subpattern instead of XML-QL's
ELEMENT_AS $B at the end).
Grouping queries can be specified more concisely by using implicit collection labels: instead of specifying the grouping variables explicitly, all variables nested inside square brackets are considered grouping variables for that grouping, unless there is another grouping (i.e., block enclosed by square brackets) closer to the variable occurrence. Using implicit collection labels, Query 1 ("Select all Essays together with their authors, i.e. author items and corresponding names.") can be expressed as:
WHERE
<bookdata>
$B: <book>
$A: <author>
<name> $N </name>
</>
</>
</>
CONSTRUCT
<results>
[<result>
$B
[<book-author>
$A
<name> $N </name>
</book-author>]
</>]
</>
No results on complexity or expressiveness of XMAS have been published.
BBQ [215] is a visual interface for XMAS that allows browsing of XML data as well as authoring of XMAS queries based on a DTD of the data to be queried.
Xcerpt http://xcerpt.org [28, 60, 61, 247, 248] is a query language designed after principles given in [57] for querying both data on the "standard Web" (e.g., XML and HTML data) and data on the Semantic Web (e.g., RDF, Topic Maps, etc. data). This Section addresses using Xcerpt on the standard Web, Section 4.5.?, on the Semantic Web.
Xcerpt's Principles:
All sample queries can be expressed in Xcerpt. In the following, Query 2, 5, 7, and 8 are omitted as they are similar to other solutions shown.
Query 1 ("Select all Essays together with their authors, i.e. author items and corresponding names.") can be expressed in Xcerpt as follows:
GOAL
results [
all result [
var Book,
all var Author,
all var AuthorName
]
]
FROM
bookdata {{
var Book → book {{
var Author → author {{
name [ var AuthorName ] }}
}}
}}
END
In the query part (enclosed by FROM and
END), a pattern of the requested data
is specified: a bookdata element with a book
child (associated with the variable Book using the
pattern restriction operator →)
that in turn has an author child (bound to the variable
Author) with a name child whose content
is bound to the Variable AuthorName.
Double curly braces (line 10) indicate an incomplete, unordered query pattern. A matching
bookdata element may have additional children not specified in
the query and the order among the children is irrelevant for the
query. Incomplete query patterns might result in
several alternative variable bindings.
Square brackets (e.g. line 13) and in the construct part
(between GOAL and
FROM) specify that the order of the children
matters. Single brackets specify that the pattern is
complete.
Similar to XMAS, Xcerpt allows to group answers
using the constructs all and some:
all t collects all possible different instances of the
subexpression t that might result from alternative variable
bindings. Grouping may be nested.
The construct term creates a result subterm for each
alternative binding of Book, and within each such
result subterm, it groups all authors and
authornames associated with that particular book.
An Xcerpt program may contain several rules, as shown in the following solution for Query 3 ("Select all data items except ontology information and translators."):
GOAL
var Result
FROM
transform [ bookdata {{ }}, result [ var Result ] ]
END
CONSTRUCT
transform [ var Element, result [ ] ]
FROM
desc var Element → /translator|category/
END
CONSTRUCT
transform [ var Element, result [ var Label [ all var Child ] ] ]
FROM
and {
desc var Element → var Label [[ var Child ]]
where {
and { var Label != "translator", var Label != "category }
},
transform [ var Child, result [ var ChildTransformed ] ]
}
END
Xcerpt rules come in two flavors:
GOAL ... FROM ... END and
CONSTRUCT ... FROM ... END.
The first may only occur once in a program,
specifies the ultimate result of the entire program. The latter form is
used for all other rules.
Here, the two lower rules transform (recursively) an input element as
specified in the query: if it is a translator or a
category the result of the transformation is empty,
otherwise the children of the element are recursively transformed and
the result of these transformations is used to reconstruct the structure
of the input data.
The desc operator (lines 10 and 17) indicates a
pattern
that is incomplete in depth.
The where clause (line 18) restricts matches
to elements that are neither translators nor
categorys.
In line 17, a label variable is used: whereas
the variable Element is bound to the entire element matched
by the pattern, Label is bound to the label of the element,
i.e. a string such as "book".
Query 4 ("Invert the relation author (from a book to an author) into a relation authored (from an author to a book).") can be expressed in Xcerpt as follows:
GOAL
bookdata [
all person [
name [ var Name ],
authored [
all book [
all var NonAuthorChildren
] group by { var Book }
]
]
]
FROM
bookdata {{
desc var Book → book [[
author {{ name [ var Name ] }},
var NonAuthorChildren → !/author/ {{ }}
]]
}}
END
All books (at any depth) are selected together
with the names of their authors and
non-author children (a negated regular expression on the label
is used for the non-author children).
For each name of an author, a
person element is constructed (note the position of
the all in line 3) containing the name
and an authored element. In the author
element all books for that author are
nested again using all with a group by
clause naming the grouping variable.
Query 6 ("Return each of the subclasses of 'Writing', together with the average number of authors per publication of that subclass.") can be expressed in Xcerpt as follows:
GOAL
results [
all category [
attributes [ id [ var ID ] ],
average-number-of-authors [
div( count( all var Author ), count( all var Book ) )
]
]
]
FROM
bookdata {{
desc category {{ attributes {{ id [ var ID ] }} }},
desc var Book → book {{
attributes {{ type [ var ID ] }},
desc var Author → author {{ }}
}}
}}
END
The average number of authors is computed in line 6
using the structural aggregation function
count over all books and authors
for a category. The join
between the id
attribute of categorys and the type
attribute of books is expressed by repeating
the same variable.
Query 9 ("Return the co-author relationship between two persons that stand in author relationships with the same book.") can be expressed in Xcerpt as follows:
GOAL
results [
all co-authors [
name [ var Author ],
name [ var CoAuthor ]
]
]
FROM
bookdata {{
desc book {{
author {{ name {{ var Author }} }},
author {{ name {{ var CoAuthor }} }}
}}
END
This query benefits from two features of Xcerpt:
book element in line 10 are
different without requiring to explicit state that the
author and the co-author must be
different.
A visual language, called visXcerpt [29, 30], has been conceived as a visual rendering of textual Xcerpt programs.
Static type checking methods have been developed for Xcerpt [55, 283].
A declarative semantics for Xcerpt has been proposed in [63, 247].
A procedural semantics for Xcerpt has been proposed in [63] in the form of a a proof procedure. An implementation of this semantic in Haskell has been realized using Constraint Programming techniques [247].
The XQuery use case [76] has been worked out in Xcerpt (cf. [174] (in German) and [45]).
Based on Xcerpt and extending it, a reactive language called XChange [58, 59] for updates and events on the Web is currently being developed.
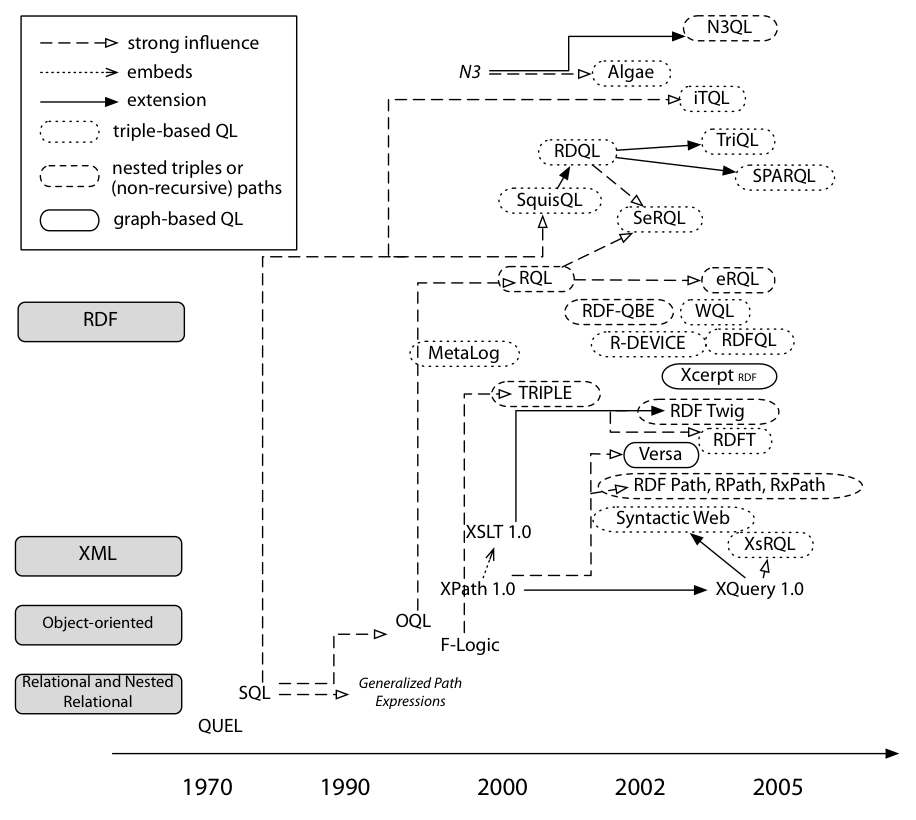
Figure 3: History of the RDF Query Languages
The SPARQL family consists of the four query languages SquishQL, RDQL, SPARQL, and TriQL. Common to all four languages in this family is that they "regard RDF as triple data without schema or ontology information unless explicitly included in the RDF source".
SquishQL [212, 213] aims at ease-of-use and similarity to SQL.
SquishQL relies on a query model for RDF influenced by [141].
SquishQL offers so-called triple patterns and conjunctions between triple patterns for specifying parts of RDF graphs to retrieved. "This results in quite a weak pattern language but it does ensure that in a result all variables are bound." [213].
SquishQL queries have the following form:
SELECT ?essay, ?author, ?authorName
>FROM http://example.org/books
WHERE (?essay, <rdf:type>, <books:Essay>),
(?essay, <books:author>, ?author),
(?author, <books:name>, ?authorName)
USING books FOR http://example.org/books#,
rdf FOR http://www.w3.org/1999/02/22-rdf-syntax-ns#
In SquishQL, Query 1 ("Select all Essays together with their authors, i.e. author items and corresponding names.") can be expressed as follows:
SELECT ?property, ?propertyValue
>FROM http://example.org/books
WHERE (?essay, <books:book-title>, "Bellum Civile")
(?essay, ?property, ?propertyValue),
USING books FOR http://example.org/books#
In SquishQL, Query 2 ("Select all data items with any relation to the book titled 'Bellum Civile'.") can (almost) be expressed as follows:
SELECT ?property, ?propertyValue
>FROM http://example.org/books
WHERE (?essay, <books:book-title>, "Bellum Civile")
(?essay, ?property, ?propertyValue),
USING books FOR http://example.org/books#
A property value can be a node with other properties that an answer to Query 2 should return. Since SquishQL has no means to express recursion, such indirect properties cannot be returned by the above query if the schema of the data is unknown or recursive.
Other sample queries cannot be expressed in SquishQL.
In a SquishQL query, the AND clause
serves to express constraints on variable values. E.g. the following
query returns the URIs of persons that have authored a
book with title 'Bellum Civile':
SELECT ?person
>FROM http://example.org/books
WHERE (?book, <books:author>, ?person)
(?book, <books:title>, ?title)
AND ?title = 'Bellum Civile'
An answer to an SquishQL query is a set of bindings for the variables occurring in the query.
SquishQL does not support RDFS.
RDQL, a "RDF Data Query Language", is an evolution of the SquishQL versions SquishQL [213], and Inkling [212] influenced by rdfDB [140].
RDQL has been recently submitted to the W3C for standardisation [213, 251, 253].
RDQL queries have the same form as SquishQL queries. As with SquishQL, an answer to an RDQL query is a set of bindings for the variables occurring in the query. Like SquishQL, RDQL supports only selection and extraction queries.
RDQL's authors see inferencing as a possible feature of an "RDF implementation", not of the query language RDQL: "if a graph implementation provides inferencing to appear as virtual triples (i.e. triples that appear in the graph but are not in the ground facts), then an RDQL query will include those triples as possible matches in triple patterns." [251]. As a consequence, queries referring to RDF/S relations such as type, set or class are cumbersome and/or complex.
The RDQLPlus (http://rdqlplus.sourceforge.net/) implementation of RDQL provides a language extension, called RIDIQL [284]. RIDIQL supports updates and a transparent use of the inference abilities of the Jena Toolkit [136].
SquishQL and RDQL queries cannot be composed.
Negation can be used in filters, or AND clauses
but not in WHERE clauses.
Disjunctions and optional matching cannot be expressed.
Although a variable in SquishQL and RDQL queries can be bound to blank nodes, there is no way to specify blank nodes in SquishQL's and RDQL's triple patterns. As a consequence, a query returning the blank nodes of a graph cannot be expressed in SquishQL and RDQL.
SquishQL and RDQL have no recursion and no iteration.
Only selection and extraction queries can be expressed in SquishQL and RDQL i.e. of the sample queries only Query 1 and (an approximation of) Query 2.
Like SquishQL, RDQL does not support RDFS concepts, although its
implementation in the Jena Toolkit [136]
supports the transitive closures of the
RDFS relations rdfs:subClassOf and
rdfs:subPropertyOf.
No formal semantics has been defined for SquishQL or RDQL.
The complexity of SquishQL and RDQL has not been investigated so far.
SPARQL [239], a "Query Language for RDF" formerly called SBrQL [238], has been developed by members of the W3C RDF Data Access Working Group. SPARQL is an extension of RDQL designed according to requirements and use cases [87] and is still under development.
SPARQL extends RDQL with facilities to:
CONSTRUCT clauses,
one new RDF graph with data from the RDF graph queried.
Like RDQL queries, the new graph can be specified with
triple patterns
or graph patterns.
DESCRIBE clauses,
"descriptions" of the resources
matching the query part. The exact meaning of "description" is not
yet defined.
OPTIONAL triple or graph query
patterns.
SPARQL queries have the following form:
PREFIX |
Specification of a name for a URI (like RDQL's USING) |
SELECT |
Returns all or some of the variables bound in the WHERE clause. |
CONSTRUCT |
Returns a RDF graph with all or some of the variable bindings. |
DESCRIBE |
Returns a description of the resources found. |
ASK |
Returns whether a query pattern matches or not |
WHERE |
list, i.e. conjunction, of query (triple or graph) patterns |
OPTIONAL |
list, i.e. conjunction, of optional (triple or graph) patterns |
AND |
boolean expression (the filter to be applied to the result) |
An extension of Query 1
("Select all Essays together with
their authors, i.e. author items and corresponding
names.") returning the translators
of a book, if there are some, can be expressed
in SPARQL as follows:
PREFIX books: http://example.org/books#
PREFIX rdf: http://www.w3.org/1999/02/22-rdf-syntax-ns#
SELECT ?essay, ?author, ?authorName, ?translator
>FROM http://example.org/books
WHERE (?essay books:author ?author),
(?author books:authorName ?authorName)
OPTIONAL (?essay books:translator ?translator)
Using the CONSTRUCT clause,
restructuring and
non-recursive inference queries can
be expressed in SPARQL.
Query 4 ("Invert the relation author (from a book to an author) into a relation authored (from an author to a book).") can be expressed in SPARQL as follows:
PREFIX books: http://example.org/books# CONSTRUCT (?y books:authored ?x) >FROM http://example.org/books WHERE (?x books:author ?y)
Query 9 ("Return the co-author relationship between two persons that stand in author relationships with the same book.") can be expressed in SPARQL as follows:
PREFIX books: http://example.org/books#
CONSTRUCT (?x books:co-author ?y)
>FROM http://example.org/books
WHERE (?book books:author ?x)
(?book books:author ?y)
AND (?x neq ?y)
TriQL extends RDQL by constructs supporting querying of named graphs [72], as introduced in TriG [40]. Named graphs allow one to filter RDF statements after their sources or authors, like in the following query: "Return the books with rating above a threshold of 5, using only information asserted by Marcus Tullius Cicero." This can be expressed in TriQL as follows:
SELECT ?books
WHERE ?graph ( ?books books:rating ?rating )
(?graph swp:assertedBy ?warrant)
(?warrant swp:authority <http://people.net/cicero>)
USING books FOR http://example.org/books#,
swp FOR <http://www.w3.org/2004/03/trix/swp-1/>
The RQL family consists of RQL, SeRQL, and eRQL. Common to these languages is that they support combining data and schema querying. Furthermore, their RDF data model deviates from the standard RDF(S) data model:
This ensure a clear separation of the 3 abstraction layers of RDF and RDFS:
rdfs:Class and rdfs:Property.
RQL, the "RDF Query Language" [84, 158, 161] is the basis for SeRQL and eRQL.
Basic schema queries. A salient feature of RQL is the use of the types from RDFS schemas. The query
subClassOf(books:Writing)
returns the sub-classes of the class books:Writing
(assuming:
USING NAMESPACE books = &http://example.org/books-rdfs#).
A similar query, using subPropertyOf instead of
subClassOf,
returns the the sub-properties of a property .
The following query returns the domain ($C1) and
range ($C2) of the property author
defined at the URI named book (The prefix
$ indicates a class
variable, i.e., a variable ranging on schema classes). It
can be expressed in RQL in three different manners:
SELECT $C1, $C2 FROM {$C1}books:author{$C2}
USING NAMESPACE books = &http://example.org/books#
SELECT C1, C2 FROM Class{C1}, Class{C2}, {;C1}books:author{;C2}
USING NAMESPACE books = &http://example.org/books#
SELECT C1, C2 FROM subClassOf(domain(book:author)){C1},
subClassOf(range(books:author)){C2}
USING NAMESPACE books = &http://example.org/books#
The query
topclass(books:Historical Essay)
returns the top of the subclass-class relation, i.e.
books:Writing.
The query
nca(books:Historical Essay, books:Historical Novel)
returns the nearest common ancestor of the classes of
'historical essays' and 'historical novels', i.e., the class
books:Essay of 'essays'.
RQL has property variables prefixed by
@ using which RDF properties can be queried
(like classes using class variables). The following query
returns the properties together with their
ranges that can be assigned to resources classified as
books:Writing:
SELECT @P, $V FROM {;books:Writing}@P{$V}
USING NAMESPACE books = &http://example.org/books#
Combining these facilities, Query 8
("Return the transitive closure of the
subClassOf relation.")
is expressible as follows:
SELECT X, Y FROM Class{X}, subClassOf(X){Y}
Data queries. With RQL, data can be retrieved by its types , by navigating to the appropriate position in the RDF graph. Restrictions can be expressed using filters. Classes, as well as properties, can be queried for their (direct and indirect12) extent. The query:
books:Writing
returns the resources classified books:Writing or
one of its sub-classes. This query can also be expressed as follows:
SELECT X FROM books:Writing{X}
Prefixing the variable X yields queries returning
only resources directly classified
as books:Writing
i.e. for which (X, rdf:type, books:Writing) "exists".
The extent of a property can be similarly retrieved.
The query
^books:author
returns the pairs of resources X, Y that
stand in the books:author relation, i.e. for which
(X, books:author, Y) exists.
RQL offers the extended dot notation, like OQL [73], for navigation in data and schema graphs. This is convenient for expressing Query 1 ("Select all Essays together with their authors, i.e. author items and corresponding names."):
SELECT X, Y, Z FROM {X;books:Essay}books:author{Y}.books:authorName{Z}
USING NAMESPACE books = &http://example.org/books#
Mixed schema and data queries. Access to data and schema can be combined, e.g.:
X;books:Essay
restricts bindings for variable X to resources with
type books:Essay.
Type information often needs to be queried:
SELECT $C, ( SELECT @P, Y FROM {Z ; ^$D} ^@P {Y}
WHERE Z = X and $D = $C )
>FROM ^$C {X}, {X}books:title{T} WHERE T = "Bellum Civile"
USING NAMESPACE books = &http://example.org/books#
This query returns the classes under which the resource with title
'Bellum Civile' is directly classified; ^$C{X} selects
the values in the direct extent of any class.
Further features of RQL are support for containers, aggregation, schema discovery.
RQL has no concept of view.
The extension RVL
[191] of RQL has a facility for specifying views,
e.g, the inverse relation of books:author:
CREATE NAMESPACE mybooks = &http://example.org/books-rdfs-extension#
VIEW authored(Y, X) FROM {X}books:author{Y}
USING NAMESPACE books = &http://example.org/books#
RQL has been criticised for
^ for calls and @ for property variables).
This has resulted in the simplifications SeRQL and eRQL of RDF.
RQL is far more expressive than most other RDF query languages.
Most sample queries, except those queries referring to the
transitive closures of arbitrary relations, can be expressed in
RQL: RDF supports only the transitive closures of
rdfs:subClassOf and
rdfs:subPropertyOf. Query
1 in RQL is given above. Query
2 ("Select all data items with any
relation to the book titled 'Bellum Civile'.") cannot be
expressed in RQL exactly, since RQL has no means to select
everything "related to some resource". However, a modified version of Query 2, where a
resource is described by its schema, is given above. Reduction
queries, e.g. Query 3 ("Select all data items except ontology
information and translators.") can often be concisely
expressed in RQL, in particular if types are available:
SELECT S, @P, O
>FROM (Resources minus (SELECT T FROM {B}books:translator{T})){S},
(Resources minus (SELECT T FROM {B}books:translator{T})){O},
{S}@P{O}
USING NAMESPACE books = &http://example.org/books#
An implementation in RQL of the restructuring Query 4 is given above in the extension RVL of RQL.
RQL is convenient for expressing aggregation queries such as Query 5 ("Return each of the subclasses of 'Writing', together with the average number of authors per publication of that subclass."):
max(SELECT Y
FROM {B;books:Writing}books:author.books:authorName{A},
{B}books:pubYear{Y}
WHERE A = "Julius Caesar")
Inference queries that do not need recursion, e.g., Query 9 ("Return the co-author relationship between two persons that stand in author relationships with the same book."), can be expressed in RQL as follows:
SELECT A1, A2 FROM {Z}books:author{A1}, {Z}books:author{A2}
WHERE A1 != A2
USING NAMESPACE books = &http://example.org/books#
Both typing rules and a semantics for RQL have been specified [161].
No formal complexity study of RDF has been published yet. An implementation of RDF is given with the so-called ICS-FORTH RDFSuite.
RQL has influenced several other RDF query languages, e.g., BrQL and SPARQL.
SeRQL [52, 67] is derived from RQL. It differs from RQL as follows:
{} for path concatenation.
FROM {Book} <books:author> {X, Y}
FROM {Book} <books:author> {X}, {Book} <books:author> {Y}
SELECT * FROM {Book} <books:title> {Title};
[ <books:translator> {Translator} [ <books:age> {Age} ] ].
FROM clause. The following SeRQL query
returns the authors of books entitled 'Bellum Civile' having a
translator named 'J.M. Carter'
(note the ; separating the different properties):
SELECT Author FROM {Book} <books:title> {"Bellum Gallicum"};
<books:translator> {} <books:translatorName> {"J.M. Carter"};
<books:author> {Author}
USING NAMESPACE books = <!http://example.org/books#>
SeRQL cannot express all sample queries. Selection and extraction queries, e.g. Queries 1 and 2,
can be expressed in SeRQL (with the same limitation as with
RQL). In contrast to RQL, SeRQL has neither set operations, nor existential or universal quantification. As a consequence,
Query 3 cannot be expressed in SeRQL.
Thanks to the CONSTRUCT
clause, SeRQL, like RQL, can express
restructuring and simple
inference queries, e.g., Query 4
("Invert the relation author
(from a book to an author) into a relation authored
(from an author to a book)."):
CONSTRUCT {Author} <mybooks:authored> {Book}
>FROM {Book} <books:author> {Author}
USING NAMESPACE books = <!http://example.org/books#>
mybooks = <!http://example.org/books-rdfs-extension#>
The Syntactic Web Approach [242, 245] consists of
rdf:instance-of-class
returning the (sequence of the) resources (represented by
their description elements) that are (direct or
indirect) instances of a class:
define function rdf:instance-of-class($t as element(description)*,
$base-name as xs:string)
as element(description)*
{
$t[rdf:type = $base-name]
,
for $i in $t[rdfs:subClassOf = $base-name]
return rdf:instance-of-class($t, string($i/@rdf:about))
}
Using the function rdf:instance-of-class and assuming
a convenient normalisation of the RDF data
Query 1
("Select all Essays together with
their authors, i.e. author items and corresponding
names.")
can be expressed as follows:
let $t := document("http://example.org/books")//description
for $essay in rdf:instance-of-class($t, "books:Essay"),
$author in $t[rdf:about = $essay/books:author]
return <result> {$essay, $author} </result>
The "Syntactic Web" approach also proposes a normalisation and XQuery functions for Topic Map.
The "Syntactic Web" approach makes it possible
Similar in spirit to the Syntactic Web Approach, TreeHugger [266] proposes to rely on XSLT for querying and transforming RDF data.
RDF Twig [277] is another extension of XSLT 1.0 with functions for querying RDF. It is based on redundant and non-redundant depth or breadth first traversals of the RDF graph, i.e. traversals that repeat or do not repeat elements in the XML-based representation of RDF. Two query mechanisms are provided: A small set of logical operations on the RDF graph, and an interface to RDQL.
Developed as part of the Python-based 4Suite XML and RDF toolkit15, Versa [219, 220, 223] is a query language for RDF inspired from, but significantly different from, XPath.
Versa can be used in lieu of XPath in the XSLT version of 4Suite. Like the Syntactic Web Approach, TreeHugger, and RDF Twig, Versa is aligned with XML.
Like XPath, Versa can be extended by externally defined functions.
Metalog differs from other RDF query languages for two reasons:
Query 1 ("Select all Essays together with their authors, i.e. author items and corresponding names.") can be expressed in Metalog as follows:
comment: some definitions of variables (or representations)
ESSAY represents the term "Essay"
from the ontology "http://example.org/books#".
AUTHORED-BY represents the verb "author"
from the ontology "http://example.org/books#".
IS represents the verb "rdf:type"
from RDF "http://www.w3.org/1999/02/22-rdf-syntax-ns#".
BELLUM_CIVILE represents the book "Bellum_Civile"
from the collection of books "http://example.org/books#".
comment: RDF triples written as Metalog statements.
BELLUM_CIVILE IS an ESSAY.
BELLUM_CIVILE is AUTHORED-BY "Julius Caesar".
BELLUM_CIVILE is AUTHORED-BY "Aulus Hirtius".
comment: a Metalog query
do you know SOMETHING that IS an ESSAY and that is AUTHORED-BY SOMEONE?
The reactive language Algae, or Algae2, is based on two concepts:
ask, assert,
and fwrule that determine whether
an expression is used to query
RDF data, insert data into the
graph, or to specify ECA-like
rules.
Algae queries can be composed. Syntactically, Algae is based on the RDF syntax N-triples [133] extended with the above-mentioned actions and with constraints written between curly brackets and specifying arithmetic or string comparisons.
Query 1 ("Select all Essays together with their authors, i.e. author items and corresponding names.") can be expressed as follows:
ns rdf = <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
ns books = <http://example.org/books#>
read <http://example.org/books> ()
ask ( ?essay rdf:type <http://example.org/books#Essay>
?essay books:author ?author .
?author books:authorName ?authorName )
collect( ?essay, ?author, ?authorName )
This query becomes more interesting if we are not only interested in the titles of essays written by 'Julius Caesar' but also want the translators of such books returned, if there are any:
ns rdf = <http://www.w3.org/1999/02/22-rdf-syntax-ns#>
ns books = <http://example.org/books#>
read <http://example.org/books> ()
ask ( ?essay rdf:type <http://example.org/books#Essay>
?essay books:author ?author .
?author books:authorName ``Julius Caesar'' .
?essay books:title ?title .
~?essay books:translator ?translator .
)
collect( ?title, ?translatorName )
~ declare translator an optional.
This query returns the following answer and "proofs":
| ?title | ?translator | Proof |
| "Bellum Civile" | "J. M. Carter" | _:1 rdf:type <http://exam...ks-rdfs#Essay>. |
_:1 books:author _:2. |
||
_:2 books:authorName "Julius Caesar". |
||
_:1 books:title "Bellum Civile". |
||
_:1 books:translator "J. M. Carter". |
Query 2 and Query 4 cannot be expressed in Algae due to the lack of closure, recursion, and negation. Queries 5 and 6 cannot be expressed in Algae due to the lack of aggregation. All other queries can be expressed in Algae, most of them requiring "extended action directives" [236].
No formal semantics has been published for Algae.
N3QL [34], is derived from Notation 3, shortN3, [35], a syntax for and extension of RDF with variables, rules, and quoting for expressing of statements about statements.
An N3QL query is an N3 expression. All N3QL reserved words are the RDF properties of an RDF (usually, but not necessarily blank) node representing the query.
Query 1 ("Select all Essays together with their authors, i.e. author items and corresponding names.") can be expressed as follows:
@prefix books: <http://example.org/books#>.
@prefix n3ql: <http://www.w3.org/2004/ql#>.
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>.
[] n3ql:select { n3ql:result n3ql:is (?book ?author ?authorName) };
n3ql:where { ?book rdf:type books:Essay;
?book books:author ?author;
?author books:authorName ?authorName }.
The answer to this query is the RDF graph
specified in the n3ql:select clause, a set of RDF
collections (indicated by the collection constructor ())
of bindings for the variables.
The following N3 rule specifies the transitive closure of a RDF property:
@prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#>.
{?x rdfs:subClassOf ?z; ?z rdfs:subClassOf ?y}
=> {?x rdfs:subClassOf ?y}
The N3 syntax for anonymous nodes, for navigating in the RDF graph using path expressions, and for quantified variables gives rise to concise expressions of queries such as "Return the books written by the author named 'Julius Caesar'." :
@prefix books: <http://example.org/books#>.
@prefix n3ql: <http://www.w3.org/2004/ql#>.
[] n3ql:select { n3ql:result n3ql:is (?book) };
n3ql:where { ?book!books:author!books:authorName ``Julius Caesar'' }.
TRIPLE [147, 259, 260] is a rule-based query, inference, and transformation language for RDF.
TRIPLE's syntax is close to F-Logic [170].
TRIPLE has been designed to address two weaknesses of previous approaches to querying RDF:
Instead of predefined RDFS-related language constructs, TRIPLE offers Horn logic rules (in F-Logic syntax) [170]. Using TRIPLE rules, one can implement features of, e.g., RDFS. Where Horn logic is not su cient, as is the case of OWL, TRIPLE is designed to be extended by external modules implementing, e.g., an OWL reasoner.
TRIPLE differs from Horn logic and Logic Programming as follows [260]:
Query 1 ("Select all Essays together with their authors, i.e. author items and corresponding names.") can be approximated as follows:
rdf := 'http://www.w3.org/1999/02/22-rdf-syntax-ns#'.
books := 'http://example.org/books#'.
booksModel := 'http://example.org/books'.
FORALL B, A, AN result(B, A, AN) <-
B[rdf:type -> books:Essay;
books:author -> A[books:authorName -> AN]]@booksModel.
This query selects only resources directly classified as
books:Essay. Query 1 is properly expressed below.
TRIPLE's rules give rise to specify RDFS' semantics
[260]:
rdf := 'http://www.w3.org/1999/02/22-rdf-syntax-ns#'.
rdfs := 'http://www.w3.org/2000/01/rdf-schema#'.
type := rdf:type.
subPropertyOf := rdfs:subPropertyOf.
subClassOf := rdfs:subClassOf.
FORALL Mdl @rdfschema(Mdl) {
transitive(subPropertyOf).
transitive(subClassOf).
FORALL O,P,V O[P->V] <-
O[P->V]@Mdl.
FORALL O,P,V O[P->V] <-
EXISTS S S[subPropertyOf->P] AND O[S->V].
FORALL O,P,V O[P->V] <-
transitive(P) AND EXISTS W (O[P->W] AND W[P->V]).
FORALL O,T O[type->T] <-
EXISTS S (S[subClassOf->T] AND O[type->S]).
}
The following rules provides Iinference from range and domain restrictions of properties:
FORALL S,T S[type-$>$T] <-
EXISTS P, O (S[P-$>$O] AND P[rdfs:domain-$>$T]).
FORALL O,T O[type->T] <-
EXISTS P, S (S[P-$>$O] AND P[rdfs:range-$>$T]).
With the rules given above, the approximation of Query 1
given above only needs to be modified so as to express the "model" it is
evaluated against: instead of @booksModel alone,
@booksModel, @rdfschema(booksModel) should be used.
Most sample queries can be expressed in TRIPLE. Aggregation queries cannot be expressed in TRIPLE.
Xcerpt http://xcerpt.org [28, 60, 61, 247, 248] is a language for querying both data on the "standard Web" (e.g., XML and HTML data) and data on the Semantic Web (e.g., RDF, Topic Maps, etc. data).
Three features of Xcerpt are convenient for querying RDF data:
subClassOf relation,
optional construct is convenient
for collecting properties of resources.
All sample queries can be expressed in Xcerpt both on the XML serialization and on the RDF serialization of the sample data. The following Xcerpt programs refer to the RDF serialization.
[44] gives two views on RDF data:
On the plain triple view, Query 1 ("Select all Essays together with their authors, i.e. author items and corresponding names.") can be expressed as follows:
DECLARE ns-prefix rdf = "http://www.w3.org/1999/02/22-rdf-syntax-ns#"
DECLARE ns-prefix books = "http://example.org/books#"
GOAL
result [
all essay [
id [ var Essay ],
all author [
id [ var Author ],
all name [ var AuthorName ]
]
]
]
FROM
and{
RDFS-TRIPLE [ var Essay:uri{}, "rdf:type":uri{}, "books:Essay":uri{} ],
RDF-TRIPLE [ var Essay:uri{}, "books:author":uri{}, var Author:uri{} ],
RDF-TRIPLE [ var Author:uri{}, "books:authorName":uri{}, var AuthorName ]
}
END
Using the prefixes declared in line 1 and 2, the query pattern
(between FROM and END)
is a conjunction of three queries. The first conjunct refers to RDFS.
This view of the RDF data contains all basic
triples as well as the triple entailed by the RDFS
semantics [148].
Using RDFS-TRIPLE instead of RDF-TRIPLE ensures
that resources from a sub-class of books:Essay are also returned.
Xcerpt shares with [242] and a few other languages the ability to construct arbitrary XML data as answer.
On Xcerpt's graph view of RDF, Query 1 can be expressed as follows:
DECLARE ns-prefix rdf = "http://www.w3.org/1999/02/22-rdf-syntax-ns#"
DECLARE ns-prefix books = "http://example.org/books#"
GOAL
result [
all essay [
id [ var Essay ],
all author [
id [ var Author ],
all name [ var AuthorName ]
]
]
]
FROM
RDFS-GRAPH {{
var Essay:uri {{
rdf:type {{ "books:Essay":uri {{ }} }},
books:author {{
var Author:uri {{
books:name {{ var AuthorName }}
}}
}}
}}
}}
END
The RDF graph view is represented by
RDF-GRAPH. The RDFS-GRAPH view
is used that extends RDF-GRAPH, i.e. RDF-TRIPLE, with RDFS-TRIPLE.
Triples are represented like in striped RDF/XML: each resource is a direct child element in RDF-GRAPH with a sub-element for each statement having this resource as object. The sub-element is labeled with the URI of the predicate and contains the object of the statement. As Xcerpt's data model is a rooted graph an not tree this can be represented without duplication of resources.
In contrast to the previous query, no conjunction is used but instead a nested pattern reflecting the structure of the RDF graph except that labeled edges are represented as nodes with edges to the elements representing their source and sink.
The following rule specifies the graph view from the triple view introduced above:
CONSTRUCT
RDF-GRAPH {
all var Subject @ var Subject:var SubjectType {
all optional var Predicate {
^var Object
},
all optional var Predicate {
var Literal
}
} }
FROM
or{
RDF-TRIPLE[
var Subject:var SubjectType{},
var Predicate:uri{},
optional var Literal → literal{{}},
optional var Object:/uri|blank/{{}}
],
RDF-TRIPLE[ /.*/:/.*/{{}}, /.*/:/.*/{{}}, var Subject:var SubjectType{{}} ]
}
END
optional at lines 16 and 17 indicates that a
part of the pattern does not have to occur in the data, but if
it does, variables are bound appropriately.
optional allows queries with alternatives to be expressed
concisely. It is crucial for RDF where all properties are optional by default.
In lines 3 and 5 the operators @ and ^ are used to build
a link, possibly yielding cycles.
Xcerpt's rules make it "serialisation transparent": For each RDF serialisation, a set of Xcerpt rules expresses a translation from or into this serialisation.
The rules for RDF/XML [25], the offcial XML serialisation, are complex and lengthy due to the high degree of flexibility RDF/XML allows. They can be found in [44]. (They are similar to functions expressing RDF/XML in XQuery given in [245]).
The following rule extracts all triples from an RXR document, i.e. a document in the Regular XML RDF format [11],. Since different types (such as URI, blank node, or literal) of subjects and objects of RDF triples are represented differently in RXR, the conversion of the RXR representation into the plain triples is performed in separate rules cf. [44].
DECLARE ns-prefix rxr = "http://ilrt.org/discovery/2004/03/rxr/"
CONSTRUCT
RDF-TRIPLE[
var Subject, var Predicate:uri{}, var Object
]
FROM
and[
rxr:graph {{
rxr:triple {
var S → rxr:subject{{}},
rxr:predicate{ attributes{ rxr:uri{ var Predicate } } },
var O → rxr:object{{}}
}
}},
RXR-RDFNODE[ var S, var Subject ],
RXR-RDFNODE[ var O, var Object ]
]
END

Figure 3: History of the Topic Map Query Languages
tolog [121, 124] has been selected in April 2004 as an initial straw-man for the ISO Topic Maps Query Language.
tolog is inspired from Logic Programming and has SQL-style constructs.
tolog provides a means for identifying a topic by its (internal)
identifier and its subject indicator. E.g., the topic (type)
Novel of the sample data can be accessed either by its
identifier Novel, or its subject indicator
i"http://example.org/books#Novel"
URI prefixes can be used:
using books for i"http://example.org/books#" gives rise
to the short form books:Novel.
tolog URI prefixes contain indicators and therefore differ from XML namespaces.
In tolog, all occurrences
of variables must be prefixed with $.
The original version of tolog [123]) has two kinds of Prolog-like predicates:
instance-of($INSTANCE, $CLASS) and
direct-instance-of($INSTANCE, $CLASS) convey the semantics
of the subclass-class relation.
authors-for-book(b1, $AUTHOR: author)
b1.
Note the association role identifying the topic
author.
The current version of tolog [122,
124]
has further built-in predicates, e.g.,
role-player and association-role, returning the
associations, association roles, occurrences, and topics.
These allow querying arbitrary topic maps without a-priori knowledge of the
types used in the topic maps.
Query 2 ("Select all data items with any relation to the book titled 'Bellum Civile'.") can be implemented as follows using only these built-in predicates:
select $RELATED from
title($BOOK, "Bellum Civile"),
related($BOOK, $RELATED)?
related($X, $Y) :- {
role-player($R1, $X), association-role($A, $R1),
association-role($A, $R2), role-player($R2, $Y) |
related($X, $Z), related($Z, $Y)
}.
Conjunctions are expressed, as in Prolog, by commas.
Disjunctions are in curly braces the disjuncts being separated by |.
The built-in predicates instance-of and
direct-instance-of can indeed be implemented using tolog rules
as follows [123]:
direct-instance-of($INSTANCE, $CLASS) :-
i"http://psi.topicmaps.org/sam/1.0/#type-instance"(
$INSTANCE : i"http://psi.topicmaps.org/sam/1.0/#instance",
$CLASS : i"http://psi.topicmaps.org/sam/1.0/#class").
super-sub($SUB, $SUPER) :-
i"http://www.topicmaps.org/xtm/1.0/core.xtm#superclass-subclass"(
$SUB : i"http://www.topicmaps.org/xtm/1.0/core.xtm#subclass",
$SUPER : i"http://www.topicmaps.org/xtm/1.0/core.xtm#superclass").
descendant-of($DESC, $ANC) :- {
super-sub($DESC, $ANC) |
super-sub($DESC, $INT), descendant-of($INT, $ANC)
}.
instance-of($INSTANCE, $CLASS) :- {
direct-instance-of($INSTANCE, $CLASS) |
direct-instance-of($INSTANCE, $DCLASS), descendant-of($DCLASS, $CLASS)
}.
Negation is available, however, its semantics is not yet specified [122].
tolog has constructs for aggregation and
sorting (although deemed
insufficient [122]),
paged queries using limit
and offset as in SQL, and modules.
Thanks to tolog's (possibly recursive) rules, Query 7
("Combine the information about the
book titled 'The Civil War' and authored by 'Julius Caesar'
with the information about the book with identifier
'bellum_civile'.")
and
Query 8
("Return the transitive closure of the
subClassOf relation.")
can be implemented in tolog.
Neither tolog's semantics nor complexity have been investigated.
AsTMa? [14, 16] is a functional query language in the style of XQuery [41].
AsTMa? offers several path languages for accessing data in topic maps.
With AsTMa?, answers can be re-structured yielding new XML documents.
Query 1 ("Select all Essays together with their authors, i.e. author items and corresponding names.") can be implemented as follows:
{ forall [$book (Writing)] in http://example.org/books
return
>book<
{$book,
forall $author in ($book -< author / author-for-book) return
>author<
{$author}
>name<{$author/bn}>/name<
>/author<
>/book< }
Query 1 can also be implemented as follows using path expressions for accessing topics and associations:
<books>
{ forall [$book (Writing)] in http://example.org/books
return
<book>
{$book,
forall [ (author-for-book)
Writing : $book
author: $author ]
in http://example.org/books return
<author>
{$author}
<name>{$author/bn}</name>
</author>
</book> }
</books>
A number of path-based query languages have been proposed for Topic Maps, cf. [15] for an overview and a plea for the inclusion of path navigation in the upcoming ISO Topic Maps query language.
XTMPath [17] is a path-based query language relying on the XTM [232] serialisation of topic maps in XML.
The following path selects all topics that are (directly) typed
Historical Novel:
topic[instanceOf/topicRef/@href = "\#Historical\_Novel"]}
This path expression reflects the XTM serialisation:
<topic id="b1"> <instanceOf> <topicRef xlink:href="#Historical_Novel"/> </instanceOf> </topic>
Note the following:
child and descendant axis and some
simple predicates (in XPath s abbreviated syntax).
child like the axis
descendant with a few exceptions, e.g.,
instanceOf.
Path vs. Logic or Navigational vs. Positional. Semantic Web query languages express basic queries using one of two paradigms, paths à la XPath, or Logic, la Logic Programming. These two paradigms can be named navigational and positional , respectively. Path-oriented navigations inherently conflict with referential transparency.
Logical Variables When Web and Semantic Web query languages have variables, they almost always are logical variables.
Referential Transparency and (Weak or Strong) Answer-Closure. Referential Transparency (i.e., within the same scope, an expression always means the same), the trait of declarative languages, is, if not fully achieved, obviously striven for by both positional and logic, query languages, especially in Semantic Web query languages. Some query languages are weakly answer-closed or answer-closed in the sense of [76], i.e., they deliver answers in the formalism of the data queried. A few query languages are strongly answer-closed, i.e., they make query programs possible that can further process data generated by these very programs.
Backtracking-free Logic Programming or Set-Oriented Functional Query Evaluation. Positional, or logic query languages that offer construct similar to rules or views, are, with a few exceptions, backtracking-free. Equivalently, they can be called set-oriented functional.
Incomplete Queries and Answers. Many query languages offer means for incomplete specifications of queries, paying tribute to the semi-structured [2] nature of data on the Web. Incomplete query specifications are extremely useful on the Semantic Web, too.
Versatile vs. Data Format Specific Query Languages. Most RDF query languages are RDF-specific, and even specifically designed for one serialisation. Data format versatile languages capable of easily accommodating XML, RDF, Topic Maps, OWL, etc. should be striven for.
Reasoning Capabilities. Not all XML query languages have views, rules, or similar concepts allowing the specification of other forms of reasoning. The same holds true of RDF query languages. Query languages capable of reasoning are needed with RDF data.
Language engineering. Abstract data types and static type checking, modules, polymorphism, and abstract machines, have clearly not yet made their way in the Web query languages.
The authors are thankful to Renzo Orsini, Ian Horrocks, Michael Kraus, and Oliver Bolzer for stimulating discussions and useful suggestions during the preparation of the report [56] that has been an important input for this survey.
This research has been funded by the European Commission and by the Swiss Federal Office for Education and Science within the 6th Framework Programme project REWERSE number 506779.
All references can be found in the article
James Bailey,
François Bry,
Tim Furche, and
Sebastian Schaffert:
"Web
and Semantic Web Query Languages: A Survey" (in PDF, 870KB).
In: Reasoning Web, First International Summer School 2005,
Norbert Eisinger and Jan Małuszynski, editors.
Springer-Verlag, LNCS 3564, 2005.
© Springer-Verlag
upon which this presentation is based.

