Fauzy is a PhD student working with Phil Bartie, Oliver Lemon, and Ben Kenwright. During the weekly SWeL meeting, Fauzy will be giving his first year progression presentation.
Abstract: This project aspires to address gaps in autonomous detection in aerial surveillance on ground objects. There are existing point cloud deep learning techniques, however many are having gaps in accuracy of detection and not developed for objects which are of interest to energy industry surveillance work. Hence the aim is to improve accuracy of object detection by exploring deep learning architecture, focusing on point cloud data manipulation and fusion methods. This Year 1 presentation covers literature review and initial implementation works.
The ACM Web Conference (the previous WWW) is the most prestigious and oldest conference focusing on the World Wide Web research and technologies. The conference began at CERN in 1994, where the Web was first born and runs annually till 2022. This year, conference management was transferred from the International World Wide Web Conferences Committee (IW3C2) to ACM. I was able to attend the conference as my RQSS paper was accepted in the PhD Symposium track (after the complex problems that occurred during registration :)). It was a real pleasure. The conference was held virtually from Lyon, France. In this post, I write a report of the sessions I’ve been in and interesting points from my own experiences.
Day 1 – Mon 25 April – Graph Learning Workshop and KGTK Tutorial
Monday, April 25 was the first day of the conference. Because I was in Iran during the conference, I was experiencing a 2.5-hour time zone difference, which made it a bit difficult for me to schedule between personal matters and the conference program. On the first day (as well as other days) there were quite interesting tracks that I had to choose because of the overlap. The Web for All track (W4A) was an example that I really wanted to participate in but I couldn’t. However, because my research focuses on the semantic web and knowledge graphs right now, I tried to attend semantic webby sessions.
For the first day, I chose the Graph Learning workshop. The workshop began with a keynote by Wenjie Zhang from the University of New South Wales. The topic of their lecture was the applications and challenges of Structure-based Large-scale Dynamic Heterogeneous Graphs Processing. In this lecture, They mentioned the improvement of efficiency in Graph Learning and having a development model for Graph Learning as the advantages of this method and considered “detecting money laundering” and “efficient suggestion in social groups” as its applications.
In Technical Session 1, I watched an interesting classic Deep Learning approach in Graph Learning called CCGG. A strong team from the high-rank universities in Iran has developed an autoregressive approach for the class-conditional graph generation. The interesting thing for me was that the team is led by Dr Soleymani Baghshah. She had previously been my Algorithm Design lecturer at the Shahid Bahonar University of Kerman. Another interesting point was that one of their evaluation datasets is protein graphs (each protein in the form of a graph of amino acids). I hoped one of the authors would be there live to answer the questions, but it was not. The presentation was also pre-recorded.
I also watched another interesting work on the Heterogeneous Information Network (HIN), called SchemaWalk. The main point of that research is using a schema-aware random walk method. In this method, the desired results can be obtained without worrying about the structure of the heterogeneous graph. The first keynote and this presentation on HIN caught my attention in the field, and I will certainly read more about heterogeneous graphs in the future.
The next interesting work was on Multi-Graph based Multi-Scenario video recommendation. I didn’t get much out of the details of the presentation, but trying to learn from multiple graphs at the same time seemed like an interesting task. Keynote 3 of the workshop was about Graph Neural Networks. Michael Bronstein from the University of Oxford had a nice presentation on how they replaced the common node-vertex perspective (discrete nature) in Graph Learning with a continuous perspective derived from physics and mathematics. I found the blog post here of the study, written by Michel. Overall, the Graph Learning workshop was very dense and quite useful. The topics will be very close to my future research (postdoc possibly), so personally, I’ll return and sit again to review many of these studies soon.
During the day, I visited the KGTK tutorial two or three times. I like their team. They are very active and have been involved in almost every major web and linked-data event in the last couple of years. KGTK tutorials are especially important to me as we are currently preparing to perform several performance and reliability tests on this tool and I am in charge of performing the technical test steps, so the more I know about the tool the better I can run experiments. In this tutorial, a good initial presentation by Hans Chalupsky overviewed the tool. Like other KGTK tutorials, this session was followed by demonstrations of Kypher language capabilities and tool’ Google Collaborate notebooks. The full material of the tutorial can be found in this repository.
The hard part of the first day for me was that my presentation was on the second day and I’ve had the stress and anxiety of that throughout the day. Surely, a considerable part of my focus was consumed on my slides, my notes and my presentation style. I was tweaking them frequently.
Day 2 – Tue 26 April – PhD Symposium
On the second day, I was supposed to present my work at the PhD symposium. I was going to attend the Beyond Facts workshop at the beginning of the day. But I needed to tweak the slides and manage my presentation timing because I was exceeding 15 minutes in the first run! Therefore, I dedicated the second day only to the PhD symposium and I was completely happy with my choice, as 7 of the 10 accepted papers were related to Semantic Web.
The PhD symposium consisted of three main sessions. Knowledge Graphs, SPARQL, and Representation and Interaction. My paper was in the first session in which 22 audiences were present. Before presenting myself, I enjoyed the “Personal Knowledge Graphs” paper. It was an interesting idea. Personal knowledge graphs are small graphs of information that are formed around an individual person. The authors have used these graphs to assist e-learning systems and have been able to make a positive impact on personal recommendations.
Then, it was my turn to speak. My presentation went very well. As I had a lot of practice and edited the slides many times, I had a good dominance in the talk and finished the presentation in exactly 15 minutes. There were 22 listeners when I started. My presentation was the last presentation of the session so my Q&A part was more flexible and took more than three minutes. The chair (Elena) asked me about the number of metrics and why there are such a high number of metrics? I answered that: during the definition phase of the framework, we tried to be as comprehensive as possible, after implementing and reviewing the results, we may want to remove some of the criteria, those that do not provide useful information. Elena also asked if we ever used human participation, questionnaires, or any human opinions data to evaluate quality. I answered that our focus is on objective metrics right now and we do not need to collect human user opinions for them (which facilitate the automaticity of the framework), but we probably will do that in the next steps.
Aleksandr, the author of the first paper of the session, also introduced a tool called Wikidata Complete, which is a kind of relation extraction and linking tool for Wikidata that also can suggest references. I’d need to look at it and see if there are any evaluations of this tool. After finishing my presentation and answering the questions, my duty at the conference has been finished. So I was happy that I could continue the conference with ease of mind.
Following the PhD symposium, at the SPARQL session, Angela gave a keynote address on Query-driven Graph Processing. In this presentation, a complete overview of data graph models, property graphs, RDF graphs and different types of graph patterns used in queries was performed. In this presentation, the concepts of Robotic Queries and Organic Queries were mentioned. Organic queries are those types of queries that humans perform on the KG endpoints. Robotic queries are those queries that are executed in automated tools by scripts, bots, and algorithms. Angela believed that robotic queries have a specific pattern. For example, these queries are on average shorter in length and use fewer variables. At the end of the presentation, there was an interesting discussion about query streaming.
At the SPARQL session, we had another presentation on Predicting SPARQL Queries Dynamics. In this presentation, the authors were working to predict possible changes in the output of a query and even estimate the dynamics of query results based on the variance of changes in the data level. They evaluated their approach on Wikidata and DBPedia.
Day 3 – Wed 27 April – Semantics
I spent the third day attending the Semantics track. The track had two sessions: Semantics: Leveraging KGs and Taxonomy Learning. The first session had problems at the beginning. The first presentation, which was a pre-recorded video, had playback problems and took about ten minutes longer. The second presentation was about learning and not had much about graph-related issues, and its timing was also a bit messy. Other presentations also were related very much to Machine Learning. But the latest presentation “Path Language Modeling over Knowledge Graphs” uses reasoning over KGs to provide explainable recommendations, special for each user. In their experiments, they have used 3 categories of Amazon consumer transaction datasets. They compared their method with 6 baseline approaches, like KGAT and CAFE and in all categories and also for all metrics (Precision, Recall, NDCG, and HR) they obtained the best results compared to baselines.
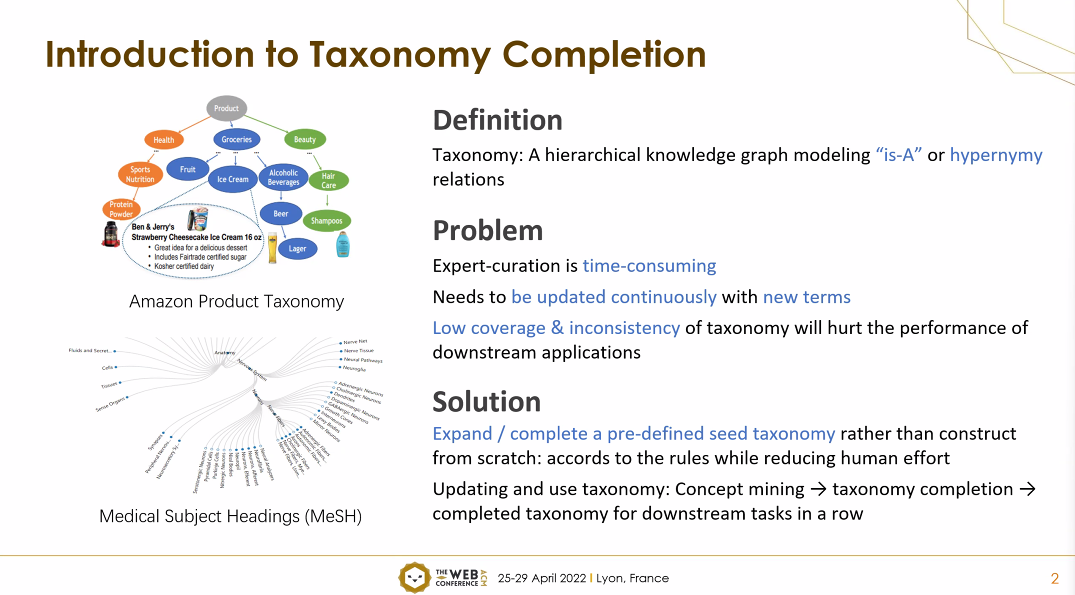
In the second session, Taxonomy Learning, there were two interesting presentations on Taxonomy Completion. It made me search a bit about the Taxonomy Completion task. The task is somehow enriching the existed taxonomies (the hierarchy of things) with rapidly expanding new concepts. In the first presentation, a new framework called Quadruple Evaluation Network(QEN) was introduced that prevents using hardly accessible word vectors for new concepts, instead, benefits from the concept of the Pretrained Language Model which enhances the performance and reduces online computational costs. In the second presentation, the authors created a “Self-Supervised Taxonomy Completion” approach using Entity Extraction Tools from raw texts. For the evaluation, they used Microsoft Academic Graph and WordNet. The notions of the session were a bit out of my knowledge and also my current research focus, but the problems and the solutions that the authors had were quite interesting, so it was added to my To-Read list! Between the two presentations about Taxonomy Completion, there was a nice talk on Explainable Machine Learning on Knowledge Graphs in the presentation of the “EvoLearner” paper.
Taxonomy Completion. Taken from Suyuchen Wang slides, The ACM Web Conference.
The afternoon was the opening day ceremony of the web conference, with the introduction of the organizers, the nominees for the best paper awards, and the official transfer of the conference from IW3C2 to ACM. The remarkable thing was how the ceremony was held in a hybrid way. The high discipline of the ceremony and its real-time direction was very remarkable.
Raphaël Troncy and Frédérique Laforest at the opening ceremony of The ACM Web Conference 2022.
Our keynote speaker on Wednesday was Prabhakar Raghavan from Google, and the title of his presentation was “Search Engines: From the Lab to the Engine Room, and Back”. One of the key points was how search engines, including Google, evolved from “keyword” processing and showing just a lot of web links to processing “entities” and finally processing “actions”. In addition to the specific style of presentation and the important content that he expressed, an important part of his presentation was about the quality of information and the problem of misinformation. In this regard, I asked a question related to my research on Wikidata references. Since a lot of information on every search comes in from the KGs, I asked the question: “Does using references and data sources, as Wikidata does, increase the quality and eliminate misinformation?” Prabhakar’s answer was that: references can improve the quality of data and affect the ranking of results, but we do not use them to remove any information. Instead, only policy violations can lead to the deletion of information.
Keynote 1 at The ACM Web Conference 2022 by Prabhakar Raghavan from Google.
Day 4 – Thu 28 April – Infrastructure
Sessions on the fourth day of the conference were generally about Recommendations. Tracks like UMAP, Search, Industry, WMCA, and Web4Good have had sessions on Recommendations. However, I did not find them very relevant to my research direction. That’s why I attended the Graphs and Infrastructure session of the Industry track. My guess was that these sessions were going to say something interesting about the infrastructure needed to process and manage big graphs, and my prediction was correct.
The first research was about Eviction Prediction in Microsoft Cloud Virtual Machines. In this paper, instead of the current hierarchical Node-Cluster system in predicting, a more efficient node-level prediction method is presented. The best part of this presentation was stating the limitations and plans to overcome them. One of the limitations of this method is that there is a lack of interpretability to use in prediction at the node level. There will also be many parameters to configure compared to traditional methods. To deal with this situation, the authors suggested using a prediction distribution instead of accurate forecasting.
Another paper was about Customer Segmentation using knowledge graphs. I really liked their explanation of the problem. A good explanation at the beginning of a presentation prepares the audiences’ minds to follow the stream and connect complex concepts together correctly. Anyway, traditional methods for Customer Segmentation are still based on questionnaires and domain experts’ opinions. In large datasets that have not been annotated, these methods will be very time-consuming. Instead of traditional methods, the authors used a KG-based clustering and tested their implementation on two customer datasets from the beverage industry.
There was also another interesting paper titled “On Reliability Scores for Knowledge Graphs”. They tried to score the data stored in an industrial KG (about product taxonomy that archives data from different sources automatically) to find only reliable data. The authors used 5 criteria for impact analysis: numerical-based, constraint-based, clustering, anomaly detection and provenance based which the last is very similar to the data quality category “trust” which I’m working on right now. This paper was the closest study to my research during the event.
The last presentation was about DC-GNN, a framework for helping E-Commerce dataset training based on Graph Neural Network (GNN). Using GNN has some benefits for training, for example, the features can be extracted topologically from the data and a relational extraction can be done. However, the huge amount of data will threaten the efficiency of algorithms and their representation of them. DC-GNN enhances the efficiency by separating traditional GNNs-based two-tower CTR prediction paradigms into three simultaneous stage methods.
After the Industry track, I joined the second keynote of the conference titled “Responsible AI: From Principles To Action” presented by Virginia Dignum from Umea University (Sweden). She had a very nice talk on the current situation of AI, the things that AI nowadays can do, like identifying patterns in images, texts and videos, extrapolating the patterns to new data and taking actions based on the patterns, as well as the things AI cannot do yet, like learning from a few examples, common scene reasoning (context and meaning), learning general concepts and combining learning and reasoning from data. She also mentioned the challenges of learning from data like the impact of the wisdom of the crowd, the impact of errors and adversaries, and the impact of biases. The main point of the talk was that we need to consider who should decide about what AI can or should do in the future and which values should be considered and how the values should be prioritized. That was a very nice talk!
Day 5 – Fri 29 April – History of Web
There were some very interesting sessions on the final day of the conference, such as Structured Data and Knowledge Graphs, Graph Search, and Social Web. But I decided to participate in the History of Web track. My reason was that this way I could get a good insight into the history of the Web, the problems that existed in the beginning, and the solutions people had for the problems to be resolved, as well as information about the evolution of the WWW conference itself since the early 90. At first, the title of the track reminded me of a part of Professor Tanenbaum’s book (Computer Networks) first chapter, and also John Naughton’s book “A Brief History of the Future” which delves into the history of the Internet.
The History of Web session consisted of papers and talks that scientifically analyzed Web development during its birthday at CERN. The first presentation, entitled “A Never-Ending Project for Humanity Called the Web”, was presented by Fabien Gandon, which shows the great changes that the Web is examining in human life. The message of this presentation was that despite the profound impact of the Web on information exchange, the Semantic Web, the Web of Things, multimedia, and authentication, much of the potential of the Web has not yet been exploited.
Then we had two guest speakers, George Metakides from the EU and Jean-François Abramatic from INRIA, who shared the history of the W3C in the first ten years on the web.
Another interesting presentation was by Damien Graux, who examined the history of the web through the lens of annual Web Conferences (formerly WWW). This study examined how academia has interacted with web technology in the last 30 years. The paper analyses statistics on the main topics and areas, authors, affiliations of the authors, countries participating in the research, citations of the web conference on other topics, and much other information. This article has historical and scientific value together. I suggest you take a look at it!
After all, I participated in the closing ceremony. Like the other parts of the conference, it was also interesting. In the end, we have been introduced to the next General Chair of The Web Conference 2022, Dr Juan Sequeda who I’m quite familiar from ISWC 2021.
Last words
In the final words, The Web Conference 2022 experience was excellent. The presentations were very interesting and understandable. The timing and discipline of the sessions were great. The chairs did their work very well. The response from the authors was nice and friendly. I liked so many presentation styles and I also learned from the speakers very much. Although the opportunity to be in France and the city of Lyon was very precious and it was not possible due to the online event, participating in the conference alongside my family from Iran made an incredible memory for me. I hope to be able to attend the conference in Austin, Texas next year, and maybe I’ll have something precious to present there 😉
The BioHackathon EuropeSubsetting Project intends to present the achievements and challenges of Wikidata subsetting on the Wikidata Reuse Days. I’m going to be in this presentation too, and I’m going to talk about the role of Wikidata References in subsetting and also about one of the Wikidata third-party tools, called WDumper as a subsetting tool. Join us if you want to know more about subsetting applications, theoretics, tools, and challenges.
This link refers to the details of the event, the speakers, and the topics covered. If you want to know more about the Subsettint Project in BioHackathon Europe, See this post.
Abstract
Often Wikidata is too big to handle. Through a sequence of BioHackathons, we have been reviewing methods to extract subsets from Wikidata to facilitate downstream reuse. We have identified a set of tools and would like to report back on our intermediate results. We will address the different applicable file formats. Natively, Wikidata data is stored in JSON, but it is also available as RDF through for example the Wikidata Query Service. Different subsetting methods use either or both of those formats as input and output. We will also address the way how to define the subset. This can be a JSON file or a Shape Expression.
I’ll be presenting my slides for the NLLP (legal NLP) workshop during EMNLP 2021. We’ve created a text processing tool that can be used as a building block for ACC (Automated Compliance Checking) using semantic parsing. This work has been done in collaboration with Ioannis Konstas, Alasdair Gray, Farhad Sadeghineko, Richard Watson and Bimal Kumar, and is part of the Intelligent Regulatory Compliance (i-ReC) project, a collaboration between Northumbria University and HWU. You can find our data and code at: https://github.com/rubenkruiper/SPaR.txt
Title: SPaR.txt – a cheap Shallow Parsing approach for Regulatory texts
Summary: Understanding written instructions is a notoriously hard task for computers. One can imagine that the task becomes harder when more and more instructions are given at once, especially when these instructions can be ambiguous or even conflicting. These reasons, amongst others, are why it is so hard to achieve (semi-)automated regulatory compliance checking — something that has been researched in the fields of Architecture, Engineering, and Construction (AEC) since the early 80s.
One necessary part of the puzzle is that a computer must recognise entities in a text, e.g., that a `party wall’ is not someone dressed up for halloween but a wall shared by multiple buildings. We’d like a computer to understand such domain-specific terms. But we don’t want to spend a lot of time defining exactly which words and word combinations belong to our domain lexicon. Therefore, we developed a tool that can help us identify groups of words (in the context of a sentence) that are likely a term of interest.
Example of the annotation scheme, see Figure 2 in our preprint.
We show that it is easy to train our tool — a simple annotation task, but also few training examples needed to achieve reasonable results. Even using just 200 annotated sentences the tool achieves 70,3% exact matches and 24,2% partial matches for entities. The output of this tool (currently focused on the AEC domain) can be used to improve Information Retrieval results and help assemble a lexicon of terminology in support of semantic parsing.
I once again attended the European BioHackathon which took place in November outside of Paris. It was another intense week with 150 developers from across Europe (and beyond) working together on 34 topics. Bioschemas was well represented in the topics and the hacking activities of the week. By the end of the week we had […]
Petros and Alasdair hacking at the BioHackathon
I once again attended the European BioHackathon which took place in November outside of Paris. It was another intense week with 150 developers from across Europe (and beyond) working together on 34 topics.
Bioschemas was well represented in the topics and the hacking activities of the week. By the end of the week we had an approach for marking up Intrinsically Disordered Proteins and Rare Disease resources. We also had several resources with newly deployed or improved Bioschemas markup.
For a fuller overview of the event and outcomes, please see the ELIXIR news item.
SPARQL (Sparql Protocol And RDF Query Language) is the W3C standard. The protocol part is usally only an issue for people writing programs that pass SPARQL queries back and forth between different machines. For most people SPARQL greatest value is as a query language for RDF – another W3C standard. RDF describes data using a collection of three-part of one statement such as emp3 has a title of Vice President.
We call each statement a triple and one triple consist of three parts these are Subject, Predicate and Object.
We can also say the Subject as an Entity Identifier, Predicate as an Attribute Name and Object as an Attribute Value.
The subject and predicate are actually represented using URIs to make it absolutely clear what we are talking about. URIs (Uniform Resource Identifier) kind of URLs and often look like them but they are not locators or addresses they are just identifiers. In our example, emp3 is the person who works in a specific company so we can represent this using URI like http://www.snee.com/hr/emp3 and title is also URI from the published ontology (In our case VCard business card ontology).
The object or third part of a triple can also be a URI if you like this way that same resource can be the object of some triples
and subject of the others which lets you connect up triples into networks of data called Graphs.
To make URIs simpler to write RDF popular Turtle syntax often shortens the URIs by having the abbreviated prefix stand-in for everything in the URI before the last part.
Any data can be represented as a collection of triples for example we can usually represent each entry of a table by using the Row Identifier is the Subject, Column Name is the Predicate and Value is the Object.
Convert Relational Database Table to RDF Statements
We can convert above table in RDF triple statements. The following RDF statements are in Turtle format of above table.
This information can give us triples for every fact on the table. Some of the property names here from the vCard vocabulary. For those properties that are not available in vCard vocabulary, I made up my own property names using my own domain name. RDF makes it easy to mix and mash standard vocabularies and customizations.
Let’s say that the employee in the above table, John Peter completed his employee orientation course twice and if we want to store both of his completed course orientation values in the RDF then there is not a problem with the RDF. But if we want to stored John’s second completed orientation value in a relational database table then it would have been a lot more difficult.
let’s look at a simple SPARQL query that retrieve some of the data from the above RDF Triples. Query 1: We want a list of all employees whose last name is Peter.
We can define the prefixes in the start of SPARQL query due to the Turtle RDF syntax, that’s why you don’t have to write absolute URIs in your queries. For most SPARQL queries it’s best to look at the Where clause first because that describe which triples we want to pull from the dataset that we are querying. The Where clause does this with one or more triple patterns which are likely triples with variables as wildcards substituted into one, two or all three of each triples parts.
In the Query 1, one triple pattern will match against triples whose predicate is the family name property from the vCard vocabulary, whose object is string Peter and whose subject is anything at all. Because this triple pattern has a variable that I named person.
SELECT Clause
The Select clause indicates which variables values we want listed after the query executes. The Query 1 only has one variable so that’s the one we want to see.
When the query executes, it finds two triples that match the specified pattern from the RDF triples set and assigned these two triples to the person variable which are the subjects e.g., emp1 and emp2. The following triples show the two matches of the above query with green colour.
Let’s executes the Query 1 and find out who are these Peters. we get the following table as a result.
From the above results, we can see that emp1 and emp2 are just identifiers. This doesn’t give us meaningful result. Query 2: Now let’s add a second triple pattern in the WHERE clause that matches on the given name of the employee, who matches the first triple pattern and stores that value in a new givenName variable.
The explanation of the Query 2 is that we need to adjust the SELECT Clause with the new variable givenName because now we want this in the result. The SPARQL query processor finds each triple that matches the first triple pattern and store the value in the person variable. When it looks for the second triple pattern in the WHERE clause, who have a triple that matches the first triple pattern. In easy words, SPARQL processor get all triples of family-name Peter along with given-name. So when we run the Query 2 we see given name values in the result.
Query 3: Let’s retrieve the given name, family name and hire date of all the employees. We can do this with a WHERE Clause that has three triple patterns one for each piece of information that we want to retrieve.
When we run the query 3, we get the following results.
FILTER Keyword
If we want to narrow down the results based on some condition, we can use a FILTER pattern. Query 4: Let’s say we want a list of employees who are hired before November 1st so the FILTER pattern specifies that we only want HD values that are less than November 1st 2015.
When we run the query 5, we get the following results.
We see only Heidi and John’s orientation dates but the other employees don’t appear at all in the results why not? Let’s look more closely at the query triple patterns. The query first looks for a triple with a given name value and then a triple with the same subject as the subject that it found to match the first triple pattern but with a family name value and then another triple with the same subject and a completed orientation value. John and Heidi each have triples that match all the query triple patterns but Imran and Duke cannot match all three triple patterns. You have noted that John actually had two triples that matched the third pattern of the query, so the query had two rows of results for him, one for each completed orientation value.
OPTIONAL Keyword
Query 6: Let’s take another example, list of all employees and if they have any their completed orientation values. We can tell query processor that matching on the third triple pattern is OPTIONAL.
This query asks for everyone with a given name and a family name and if they have a completed orientation value it will show the following result.
NOT EXISTS Keyword
Query 7: Next let’s say that Heidi is scheduling a new orientation meeting and wants to know who to invite, in other words she wants to list all employees who do not have a completed orientation value. Her query asks for everyone’s given and family names but only if for any employee who matches those first two triple patterns no triple exists that lists a completed orientation value for that employee. We do this with the keywords NOT EXISTS.
When we run the query 7, we get the following results.
BIND Keyword
So far, the only way we have seen to store a value in a variable is to include that variable in a triple pattern for the query processor to match against some part of triple. We can use the bind keyword to store whatever we like in a variable.
When we run the above query, we get the following results.
This can be especially useful when the BIND expression uses values from other variables and calls some of SPARQL broad range of available functions to create a new value. In the following query the bind statement uses SPARQL’s concat function to concatenate the given name value stored by the first triple pattern a space and the family name value stored by the second triple pattern. It stores the result of this concatenation in a new variable called fullName.
When we run the above query, we get the following results with new full name value for each employee.
CONSTRUCT Clause
All the queries we have seen so far have been SELECT queries which are like SQL SELECT statements. A Sparql construct query uses the same kind of WHERE clauses that a SELECT query can use but it can use the values stored in the variables to create the new triples.
When we run the above query, we get the following new triples.
Note that how the triple pattern showing the triple to construct is inside of curly braces. These curly braces can enclose multiple triple patterns which is a common practice when for example a construct query takes data conforming to one modal and creates triples conforming to another. The construction queries are great for data integration projects.
I was away from September 22 – 28, 2019 for attending the 15th eScience Conference, San Diego, California, USA. It was my first experience to attend the international conference in which I presented my paper. The objective of the eScience Conference is to promote innovation in collaborative, computationally- or data-intensive research across all disciplines, throughout the research lifecycle. This conference was also co-located with the Gateways 2019 conference. The two conferences will offer a shared keynote, presentations about mutually interesting topics, and a shared evening reception, as well as opportunities for mingling during the breaks. Conference attendees will have the option to register for one or both conferences, in full or in part. These two audiences share interests, content, and culture. This is an opportunity to attend both events!
This was the great trip for me because I learnt a lot from it by attending the relevant workshop, presentation and keynotes. My presentation was in Research Object workshop 2019. There were total six workshops
My workshop was on the first day. So, I was very nervous about my presentation. This RO workshop consists of 15 members that includes professors with lot of research experience.
Poster eScience 2019
In the Research Object workshop, first presented the Research Objects by Carole Goble that a merging approach to the publication, and exchange of scholarly information on the Web. Research Objects aim to improve reuse and reproducibility by:
Supporting the publication of more than just PDFs, making data, code, and other resources first class citizens of scholarship
Recognizing that there is often a need to publish collections of these resources together as one shareable, cite-able resource.
Enriching these resources and collections with any and all additional information required to make research reusable, and reproducible!
Research objects are not just data, not just collections, but any digital resource that aims to go beyond the PDF for scholarly publishing!
Welcome Research Objects 2019 By Carole Goble
The keynote speaker was the Bertram Ludäscher, who presented: From Research Objects to Reproducible Science Tales.
In his presentation, he talked about what we mean by reproducibility, identify tool and thinking gaps, and bridging gaps.
Another presentation about RO-Crate, the new advancement in the Research Object presented by Stian Soiland-Reyes. This is increasingly important as researchers now rely heavily on computational analysis, yet they are facing a reproducibility crisis as key components are often not sufficiently tracked, archived or reported. They are developing Research Object Crate (or RO-Crate for short), a lightweight approach to package research data with their structured metadata, based on schema.org annotations in a formalized JSON-LD format that can be used independent of infrastructure to encourage FAIR sharing of reproducible datasets and analytical methods.
After attending the five more presentations, we would go for the lunch in front of the sea view. It was very amazing view while taking the lunch. After finishing the lunch, first presentation was mine. So, I presented work at the Data Quality Issues in Current Nanopublications by performing the data analysis of using existing datasets (DisGeNET, neXtProt, LIDDI, OpenBEL, WikiPathways).
In my presentation, I discussed the data quality issues in the nanopublications while generating the nanopublications. The data quality issues mean that
General lack of provenance and publication information
Misuse of authoring/publishing ontology terms
Lack of domain expertise and database content
So there is the Need for domain best practice guidelines for generating the good quality nanopublications. Our analysis is also available on the GitHub.
The Second Day start with the keynote Speaker Randy Olson, He discussed about the framework ABT (AND, But and Therefore) that The ABT Narrative Template is a new tool for organizing the narrative structure of any amount of content. It is at the core of storytelling, logic, reason, argument and the scientific method. How to divide the big sentences into the ABT format and solve the problem. It is the idea of shrinking a narrative thread down to a single sentence using three connector words: and, but, therefore.
In this day, lot of other presentations were held about the eScience and Gateway and challenges about these terminologies.
Third Day (26th, September 2019)
The Third Day start with the keynote Speaker Manish Parashar, He discussed about the Exploring the Future of Facilities-based, Driven-Driven Science.
In this day, lot of other presentations were held about the eScience and Gateway and challenges about these terminologies.
3rd day in #eScience2019 conference with Keynote: Manish Parashar on "Exploring the Future of Facilities-based, Driven-Driven Science" pic.twitter.com/jfyhJOqTYx
After the lunch on the same day, Another keynote Speaker Maryann E Martone, He discussed about the Exploring the Neuroscience as an open, FAIR and citable discipline.
Today’s final session with Keynote: Maryann Martone on "Neuroscience as an open, FAIR and citable discipline" pic.twitter.com/RCMeK4FLiI
The fourth Day (last day of conference) start with the keynote Speaker Dieter Kranzlmüller, He discussed about the Environmental Computing on SuperMUC-NG – A Partnership between Computer and Domain Sciences.
Today is the final session in #eScience2019 conference with Keynote: Dieter Kranzlmüller on "Environmental Computing on SuperMUC-NG – A Partnership between Computer and Domain Sciences" pic.twitter.com/f1xaiLuu4k
Overall, I really enjoyed the conference. I got a chance to spend sometime with a bunch of members of the community and it’s exciting to see the continued excitement and the number of new research questions.
Speaker: Imran Asif Date: Wednesday 18 September 2019 Time: 11:15 – 12:15 Venue: CM T.01 EM1.58
Imran will give a practice version of his workshop paper that will be given at Research Objects 2019 (RO2019).
Abstract: Nanopublications are a granular way of publishing scientific claims together with their associated provenance and publication information. More than 10 million nanopublications have been published by a handful of researchers covering a wide range of topics within the life sciences. We were motivated to replicate an existing analysis of these nanopublications, but then went deeper into the structure of the existing nanopublications. In this paper, we analyse the usage of nanopublications by investigating the distribution of triples in each part and discuss the data quality issues raised by this analysis. From this analysis we argue that there is a need for the community to develop a set of community guidelines for the modelling of nanopublications.
During the summer, BridgeDb has had a Google Summer of Code student working on extending the system to work with secondary identifiers; these are alternative identifiers for a given resource. The student Manas Awasthi has maintained a blog of his experiences. Below are some excerpts of his activity. Google Summer of Code 2019: Dream to […]
During the summer, BridgeDb has had a Google Summer of Code student working on extending the system to work with secondary identifiers; these are alternative identifiers for a given resource.
The student Manas Awasthi has maintained a blog of his experiences. Below are some excerpts of his activity.
Google Summer of Code 2019: Dream to Reality Manas Awasthi May 28 · 3 min read Google Summer of Code, an annual Google program which encourages open source contribution from students. The term I was introduced to by my seniors in my freshman year. Having no clue about open source, I started gathering knowledge about ‘How to contribute to open source projects?’ Then I came across version control, being a freshman it was an unknown territory for me. I started using Github for my personal projects which gave me a better understanding of how to use it. Version Control Service was off the checklists. By the time all this was done Google Summer of Code 2018 was announced.
Google Summer of Code 2019: Dream to Reality Manas Awasthi Jun 12 · 3 min read The Coding Period: The First Two Weeks The coding period of Google Summer of Code started on 27th of May, at the time of publishing it’s been more than 2 weeks, here I am writing this blog to discuss what I have done over the past two weeks, and what a ride it has been already. Plenty of coding along with plenty of learning. From the code base to the test suite.
Google Summer of Code 2019: Dream to Reality Manas Awasthi Jun 22 · 3 min read The Coding Period: Week 3 — Week 4 Hola Amigos!!! Let’s discuss my progress through week 3 and 4 of GSoC’s coding period. So the major part of what I was doing this week was to add support for the secondary identifier (err!!! whats that) to BridgeDb.
Google Summer of Code 2019: Dream to Reality Manas Awasthi Aug 21 · 3 min read Hey Folks, this is probably the last blog in this series outlining my journey as a GSoC student. In this blog I’ll go through the functionality I have added over the summer and why the end-users should use it.
Below is the opening exert from the second FAIRplus Newsletter: Though FAIRplus has been running for just six months, there is already a lot to talk about. Our two task-focused ‘Squads’ have booted up and begun the FAIRification of the first set of four pilot datasets, our industry partners in EFPIA organised the first ‘Bring Your Own Data’ […]
You can read about these activities in this second FAIRplus newsletter. On top of that, we bring you an update on upcoming events, news from our partners and also a new section ‘Track our progress’ where you can check for yourself how we are progressing towards our goals and what Deliverables and reports we’ve recently submitted.
Finally, we’ve launched our own LinkedIn page. Besides regular updates on our activities, it will also feature job opportunities and news from the FAIRplus partners.
The next FAIRplus Newsletter will come out in November 2019. In it we’ll present the FAIRplus Fellowship programme, report on the FAIR workshop in October and more.
We wish you a relaxing Summer and look forward to meeting you at our events!