Alasdair Gray and I have had Anna Grant working with us for the last 12 weeks on an Equate Scotland Technology Placement project looking at how we can represent course information as linked data. As I wrote at the beginning of the project, for me this was of interest in relation to work on the use of schema.org … Continue reading A short project on linking course data →
Alasdair Gray and I have had Anna Grant working with us for the last 12 weeks on an Equate Scotland Technology Placement project looking at how we can represent course information as linked data. As I wrote at the beginning of the project, for me this was of interest in relation to work on the use of schema.org to describe courses; for the department as a whole it relates to how we can access course-related information internally to view information such as the articulation of related learning outcomes from courses at different stages of a programme, and how data could be published and linked to datasets from other organisations such as accrediting bodies or funders. We avoided any student-related data such as enrolments and grades. The objectives for Anna’s work were ambitious: survey existing HE open data and ontologies in use; design an ontology that we can use; develop an interface we can use to create and publish our course data. Anna made great progress on all three fronts. Most of what follows is lifted from her report.
(Aside: at HW we run 4-year programmes in computer science which are composed of courses; I know many other institution run 3/4-year courses which are comprised of modules. Talking more generally, course is usefully ambiguous to cover both levels of granularity; programme and module seem unambiguous.)
A few Universities have already embarked on a similar projects, notably the Open University, Oxford University and Southampton University in the UK, and Muenster and the American University of Beirut elsewhere. Southampton was one of the first Universities to take the open linked data approached and as such they developed their own bespoke ontology. Oxford has predominantly used the XCRI ontology (see below for information on the standard education ontologies mentioned here) to represent data, additionally they have used MLO, dcterms, skos and a few resource types that they have defined in their own ontology. The Open University has the richest data available, the approach they took was to use many ontologies. Muenster developed the TEACH ontology, and the American University of Beirut used the CourseWare and AIISO ontologies.
The ontologies reviewed were: AIISO, Teach, CourseWare, XCRI, MLO, ECIM and CEDS. A live working draft of the summary / review for these is available for comment as a Google Doc.
Aiiso (Academic Institution Internal Structure Ontology) is an excellent ontology for what it is designed for but as it says, it aims to describe the structure of an institution and doesn’t offer a huge amount in the way of particular properties of a course. Teach is a better fit in terms of having the kind of properties that we wished to use to describe a course, however doesn’t give any kind of representation of the provider of the course. CourseWare is a simple ontology with only four classes and many properties with with Course as the domain, the trouble with this ontology is that it is closely related to the Aktors ontology which is no longer defined anywhere online.
XCRI and MLO are designed for the advertising of courses and as such they miss out some of the features of a course that would be represented in internal course descriptions such as assessment method and learning outcomes. Neither of these ontologies show the difference between a programme and a module. ECIM is an extension of MLO which provides a common format for representing credits awarded for completion of a learning opportunity.
CEDS (Common Education Data Standards) is an American ontology which provides a shared vocabulary for educational data from preschool right up to adult education. The benefits of which are, that data can be compared and exchanged in a consistent way. It has data domains for assessment, learning standards, learning resources, authentication and authorisation. Additionally it provides domains for different stages of education e.g. post-secondary education. CEDS is ambitious in that it represents all levels of education and as such is a very complex and detailed ontology.
XCRI, MLO (+ ECIM) and CEDS can be grouped together in that they differentiate between a course specification and a course instance, offering or section. The specification being the parts of a course that remain consistent from one presentation to the next, whereas the instance defines those aspects of a course that vary between presentations for example location or start date. The advantage of this is that there will be a smaller amount of data that will require updating between years/offerings.
An initial draft of a Heriot Watt schema applying all the ontologies available was made. It was a mess, however it became apparent the MLO was the predominant ontology. So we chose to use MLO where possible and then use other ontologies where required. This iteration resulted in a course instance becoming both an MLO learning opportunity instance and a TEACH course in order to be able to use all the properties required. Even using this mix of ontologies we still needed to mint our own terms. This approach was a bit complex and TEACH does not seem to be widely used, we therefore decided to use MLO alone and extend it to fit our data in a similar way that already started by ECIM.
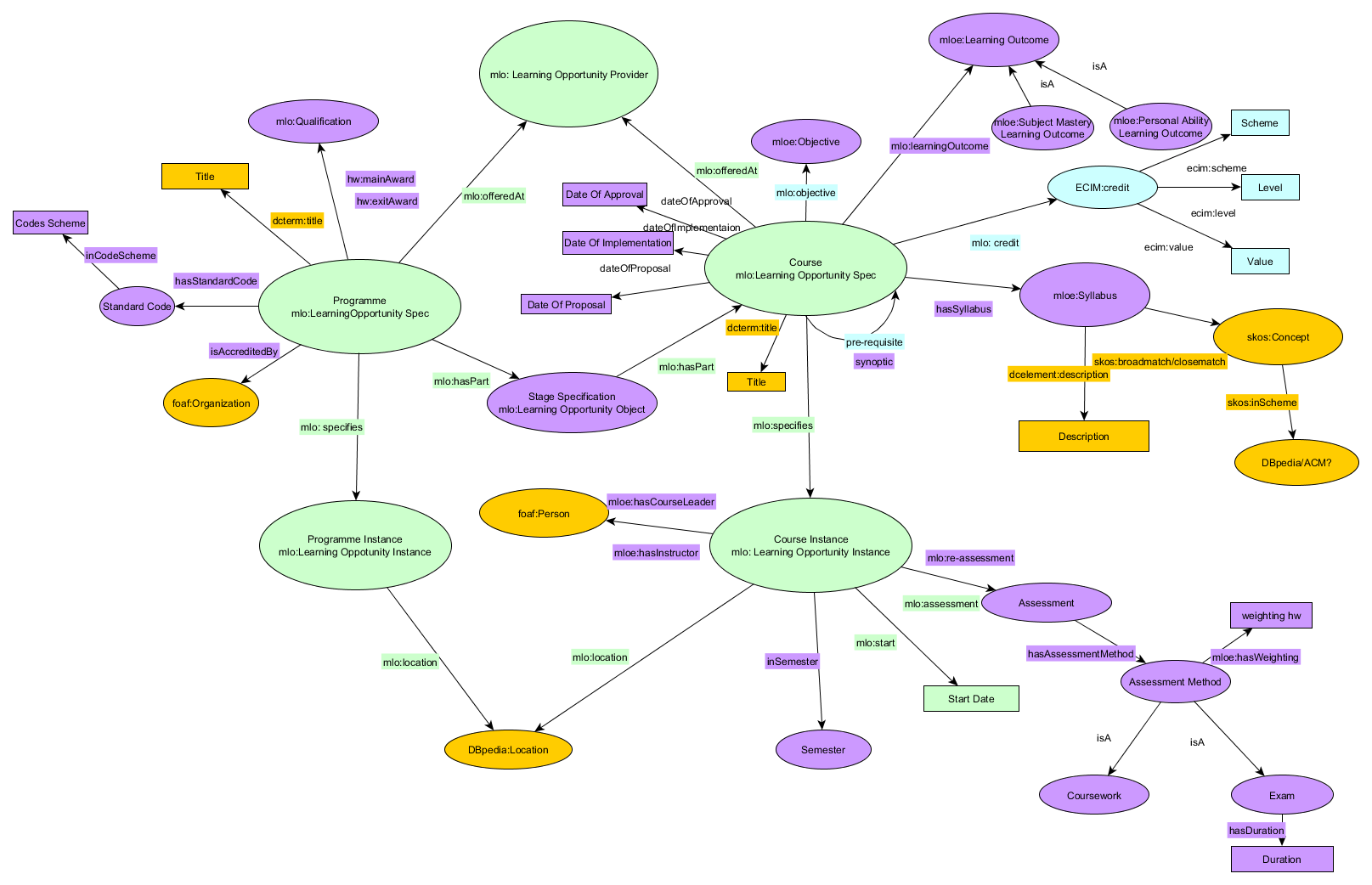
The final draft is shown below. Key: Green= MLO, Purple=MLO extension, Blue=ECIM / previous alteration to MLO Yellow= generic ontologies such as Dublin core and SKOS. In brief, we used subtypes of MLO Learning Opportunities to describe both programmes and modules. The distinction between information that is at the course specification level and that which is at the course instance level was made on the basis of whether changing the information required committee approval. So things that can be changed year on year without approval such as location, course leader and other teaching staff are associated with course instance; things that are more stable and require approval such as syllabus, learning outcomes, assessment methods are at course specification level.
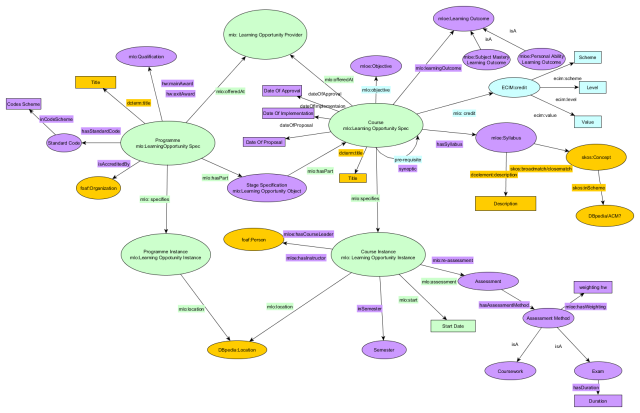
We also created some instance data for Computer Science courses at Heriot-Watt. For this we use Semantic MediaWiki (with the Semantic bundle). Semantic forms were used for inputting course information, the input from the forms is then shown as a wiki page. Categories in mediawiki are akin to classes, properties are used to link one page to another and also to relate the subject of the page to its associated literals. An input form has the properties inbuilt such that each field in the form has a property related to it. Essentially the item described by the form will become the object in the stored triple, the property associated with a field within the form will form the predicate of the stored triple and the input to the field will form the subject of a triple. A field can be set such that multiple values can be entered if separated by commas, and in this case a triple will be formed for each value. I think there is a useful piece of work that could be done comparing various tools for creating linked data (e.g. Semantic MediaWiki, Calimachus, Marmotta) and evaluating whether other approaches (e.g. WordPress extensions) may improve on them. If you know of anything along such lines please let me know.
We have little more work to do in representing the ontology in Protege and creating more instance data, watch this space for updates and a more detailed description than the image above. We would also like to evaluate the ontology more fully against potential use cases and against other institutions data.
Anna has finished her work here now and returns to Edinburgh Napier University to finish her Master’s project. Alasdair and I think she has done a really impressive job, not least considering she had no previous experience with RDF and semantic technologies. We’ve also found her a pleasure to work with and would like to thank her for her efforts on this project.

 More good news: the
More good news: the 
 I was lucky enough to go to Florence for some of the pre WWW2015 conference workshops because
I was lucky enough to go to Florence for some of the pre WWW2015 conference workshops because 