6 Genetic Programming
Genetic programming is a computer algorithm which designs and optimises programs using
a process modelled upon biological evolution. This chapter introduces the family of
algorithms to which genetic programming belongs, introduces genetic programming,
discusses its behaviour and limitations, and reviews derivative approaches.
6.1 Evolutionary Computation
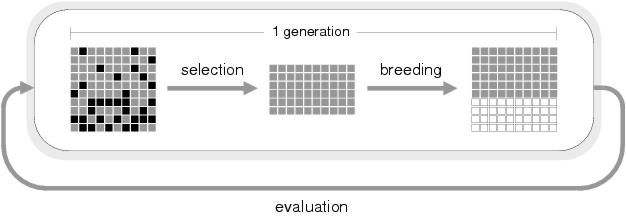
Figure 6.1: One generation of an evolutionary algorithm. Having evaluated the solutions
within the population, selection removes the relatively poor solutions (shown black)
and breeding generates new solutions (white) from the surviving, relatively good,
solutions (grey).
Evolutionary computation (EC) is an approach to search, optimisation and design which
uses a family of approaches called evolutionary algorithms (EAs) that use evolutionary
processes to evolve any kind of entity which may be represented on a computer. Most
evolutionary algorithms model the biological process of evolution. Using terms from
Chapter 1, this kind of process is group-based and involves both competitive and
co-operative mechanisms during the evolution of the group: and in this respect is
related to other group-based search algorithms such as particle swarm, memetic, tabu,
and ant algorithms.
Central to an evolutionary algorithm is the data structure which holds evolving
entities: the population. At the start of an evolutionary run, this structure is
initialised to contain a group of candidate solutions to some problem. Typically
these solutions are randomly generated. Consequently most will be far from optimal, but
nevertheless all are evaluated using some fitness function which determines
their relative ability to solve the problem and assigns each candidate solution a
respective fitness value. Following evaluation, the evolutionary algorithm
applies a selection mechanism which removes the least fit candidate solutions
from the population. After this, a breeding process fills the vacated population slots
with new candidate solutions which it derives from existing solutions. At this point
the population consists only of relatively fit solutions from the initial population
and their derivatives. Accordingly, it is expected that the average fitness of the
population will have increased. The process of evaluation, selection, and breeding is
repeated over and over again - with hopefully a higher average fitness after each
iteration - until either the population contains an optimal solution, or the entire
population converges upon sub-optimal solutions. Figure 6.1
illustrates this process.
Different classes of evolutionary algorithm differ in the way in which they represent
solutions and the way in which they derive new solutions from existing solutions.
Individual algorithms also differ markedly in the size of populations which they use,
the way in which they carry out selection, and in the proportion of the population
which they replace during each selection-breeding cycle. It is common to classify
particular evolutionary algorithms as being either genetic algorithms
[Holland, 1975], evolution strategies [Rechenberg, 1973], evolutionary
programming [Fogel et al., 1966], or genetic programming [Koza, 1992]: although this
form of classification arguably introduces artificial barriers to common issues. Whilst
this thesis is concerned primarily with genetic programming, the following chapters
also make significant mention of genetic algorithms; and for this reason they are
briefly reviewed in the following section.
6.1.1 Genetic Algorithms
The genetic algorithm (GA) is an evolutionary algorithm which mimics both the
representation and variation mechanisms of biological evolution. A GA candidate
solution is represented using a linear string in analogy to a biological chromosome.
Accordingly, GA practitioners use biological terms to describe the components of
candidate solutions: whereby each position within a GA chromosome is known as a gene
locus (or just a gene) and its value is an allele. Historically, GA chromosomes are
fixed length binary strings (although some GAs use variable length strings and
higher-cardinality alphabets - including real numbers). New solutions are constructed
from existing solutions using operators whose effects resemble the action of mutation
and recombination upon biological chromosomes. Mutation operators randomly change the
allele of a particular gene locus whereas crossover recombines groups of contiguous
genes from two or more existing chromosomes. The mechanics of individual GAs vary
considerably. However, most GAs are generational: meaning that the entire
population is replaced during each iteration; and most have a selection mechanism that
allocates each solution's contribution to the next generation roughly in proportion to
its relative fitness in the current generation. Consequently, the best solutions have
their genes well represented in the next generation whilst the worst solutions tend to
give no contribution to the next generation.
Crossover is traditionally considered the dominant search operator in GAs, and mutation
is considered a background operator which replenishes genetic diversity lost during
selection. Crossover proceeds as follows: two chromosomes are aligned, a number of
crossover points are selected randomly along the chromosome lengths, and groups of
genes between every other pair of crossover points are swapped between the two
chromosomes. Genetic linkage is said to occur between alleles at different gene loci
that remain together following recombination. Given the way that crossover works,
genetic linkage is most likely to occur between alleles at gene loci which have
proximal positions within the chromosome. This means that GAs must function as a result
of propagating small groups of alleles found close together within chromosomes: groups
that are known as building blocks within the GA literature [Goldberg, 1989].
However, this is only useful if chromosomal building blocks correspond to building
blocks found within the problem domain. If this is not the case, or particularly if the
problem's building blocks are represented by groups of highly spaced alleles,
performance is likely to be impaired. Such problems can sometimes be solved by
re-arranging gene loci within the chromosome. GAs which do this automatically are known
as linkage learning GAs and are discussed in section 7.5.
6.2 Conventional Genetic Programming
Genetic programming (GP) is a generic term used to mean an evolutionary computation
system which is used to evolve programs. Early forms of GP can be traced back to
Friedberg [1958] and Cramer [1985]. The first GP system to bear the name
`Genetic Programming' was devised by Koza15 [Koza, 1992]; and
this, by virtue of being the first successfully applied and widely recognised form of
GP, forms the basis of conventional GP systems.
Koza's genetic programming represents programs by their parse trees. A parse tree is a
tree-structure which captures the executional ordering of the functional components
within a program: such that a program output appears at the root node; functions are
internal tree nodes; a function's arguments are given by its child nodes; and terminal
arguments are found at leaf nodes. A parse tree is a particularly natural structure for
representing programs in LISP; the language Koza first used for genetic programming.
This is one reason why the parse tree was chosen as a representation for genetic
programming. A problem, in GP, is specified by a fitness function, a function set, and
a terminal set. The function and terminal sets determine from which components a
program may be constructed; and the fitness function measures how close a particular
program's outputs are to the problem's required outputs. The initial population is
filled with programs constructed randomly from components in the function and terminal
sets16.
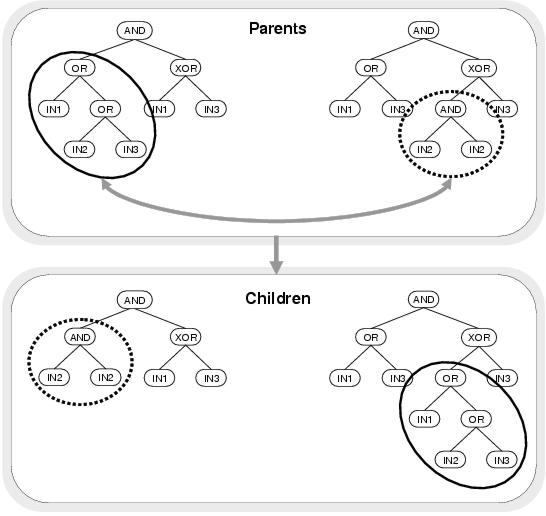
Figure 6.2: Sub-tree crossover creating new programs from existing programs.
Sub-trees are selected randomly from two existing parse trees
and are then swapped to produce child parse trees.
Conventional GP derives new programs from existing programs using three different
methods. Point mutation randomly changes the functions or terminals found at a
proportion of the nodes within a parse tree. The number of nodes to be mutated are
determined by a probabilistic parameter called the mutation rate. Sub-tree mutation, by
comparison, randomly changes entire sub-trees; building new sub-trees out of randomly
chosen functions and terminals. Sub-tree crossover, which is traditionally considered
the most important GP variation operator, constructs new program parse trees by
swapping randomly chosen sub-trees between existing parse trees: an example of which is
depicted in figure 6.2.
Genetic programming has been applied within a huge variety of problem domains. A number
of these are used primarily for comparing the performance of particular GP approaches:
algebraic symbolic regression, for example. In other domains, GP has been used to
re-discover solutions which had previously been invented by humans; as well as
discovering new solutions of comparable performance (see, for example,
[Miller et al., 2000]). In yet other domains, GP has evolved solutions to problems which
had not previously been solved by humans. This includes certain quantum computing
algorithms and problems in biological understanding (e.g. [Koza, 2001]).
6.3 Problems with Recombination
Despite its successes, GP is known to have behavioural problems which limit its
applicability and performance. Most significant of these is the manner in which parse
trees are affected by sub-tree crossover. First, it has been argued that sub-tree
crossover does not perform meaningful recombination and does not therefore aid search
performance. This argument is reviewed in this section. Second, sub-tree crossover is
thought instrumental in causing program size bloat; an issue which is discussed in the
following section.
In [Koza, 1992] it is argued that sub-tree crossover is the dominant operator
within genetic programming: responsible for exploiting existing genetic material in the
search for fitter solutions. However, experimental evidence
[Angeline, 1997,Luke and Spector, 1997,Luke and Spector, 1998] suggests otherwise. In [Angeline, 1997], the
author compares the performance of sub-tree crossover against an operator - headless
chicken crossover - which resembles crossover, but which actually carries out a
behaviour more akin to sub-tree mutation. This operator works by performing a sub-tree
exchange between an existing parse tree and a randomly generated parse tree of a
similar size. Across three problem domains, the difference between the performance of
sub-tree crossover alone and headless chicken crossover alone is statistically
insignificant: suggesting that the behaviour of sub-tree crossover is no better than
that of macro-mutation. However (despite what the author suggests) the behaviour of
sub-tree crossover is not equivalent to headless chicken crossover; given that sub-tree
crossover is only able to use genetic material which already exists within the
population. It could be argued that sub-tree crossover performed badly in these
experiments because of the lack of mutation, upon which it would ordinarily rely to
introduce new genetic material and maintain diversity within the population.
However, more recent work by Luke and Spector [1997],Luke and Spector [1998] also suggests that sub-tree
crossover performs little better than macro-mutation. Luke and Spector compare runs
with 90% sub-tree crossover and 10% sub-tree mutation with runs of 10% sub-tree
crossover and 90% sub-tree mutation across a range of problem domains and parameter
values. Their results indicate that whilst crossover does perform slightly better than
sub-tree mutation overall, the benefit is slight and in most cases the difference in
performance is statistically insignificant. The authors also note that for certain
problems (including symbolic regression), crossover performs better for large
populations and few generations whilst sub-tree mutation performs better for small
populations and large numbers of generations. However, this does not hold for all
problems.
This poor performance has perhaps less to do with crossover than it has to do with the
parse tree representation. For GAs, it is fairly well accepted that crossover improves
performance for problem domains with reasonably low levels of epistasis and with a
reasonable arrangement of genes within a chromosome i.e. in situations where building
blocks can be readily processed by crossover. After all, recombination is logically a
useful operation - it enables co-operative evolution by allowing information exchange
within a population. Furthermore, it appears to play a primary role within eukaryotic
evolution.
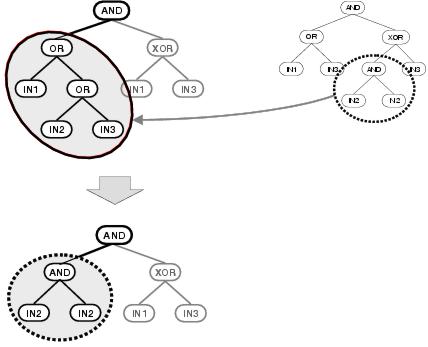
Figure 6.3: Loss of context following sub-tree crossover.
Sub-tree crossover is a natural recombination operator for parse trees. However, by
exchanging randomly chosen sub-trees between programs, it does not carry out a
logically meaningful operation. This is illustrated in figure
6.3. In this example, a random sub-tree is selected in an
existing parse tree and is replaced by a sub-tree which is randomly selected from
another parse tree. These parent parse trees have significant shared behaviours: both
apply an AND function to the outputs of
OR and
XOR
functions, and both have a left-hand branch which calculates the
OR of a
number of input terminals; so in principal it would seem that they have compatible
information to share. However, because the exchanged sub-trees are selected from
different positions and have different size, shape and functionality, the behaviour of
the resulting child solution bears little resemblance to either parent. The behaviour
of each of these programs is determined by the output of the
AND function at
the top of the program. The output of a function depends upon both the function it
applies and upon its input context: the inputs to which it applies the function.
Consequently, if its input context changes considerably, then so does its output. Given
that most possible programs will generate very poor solutions to a problem, and that
the parent programs are presumably relatively good at solving the problem, a
considerable change in output behaviour is likely to result in a program with low
fitness. In the example, one of the AND function's inputs changes from being
the OR of three inputs to the
AND of a single input with itself:
leading to a significant change in output behaviour.
Since it is unlikely that sub-tree crossover will exchange sub-trees with similar
position, size, shape, or behaviour, most GP sub-tree crossovers will lead to child
programs which are considerably less fit than their parents. In essence, this happens
because a component's context is recorded in terms of its position within a parse tree;
and because sub-tree crossover does not preserve the positions of components. Later in
this thesis it will be argued that this failing is as much the fault of the program's
representation as it is the fault of the sub-tree crossover operator.
6.4 Solution Size Evolution and Bloat
Parse trees are variable length structures and, in the absence of any mechanisms of
constraint, may change size freely during the course of evolution. Unfortunately, in GP
there is a tendency for parse trees to grow, rather than shrink, over time. This leads
to a phenomenon called bloat whereby programs become larger and larger without
significant improvement in function. In standard GP, program bloat has nearly quadratic
complexity [Langdon, 2000a]. This causes a number of problems. First, it places a
strain on both storage and executional resources. Second, it leads to programs which
are large, complex, inefficient and hard to interpret. Third, bloat usually takes the
form of an increase in non-functional code; and given that this code comprises most of
the program, it becomes the target of most crossover and mutation events: protecting
the functional code from change and ultimately reducing the effectiveness of evolution.
The role of non-functional code in GP is discussed in more detail in section
7.4.1. Although the exact cause of bloat is not known, a number
of mechanisms have been identified which appear to contribute to the effect. These are
replication accuracy, removal bias, search space bias, and operator bias; and are
discussed below.
The replication accuracy theory of bloat
[Blickle and Thiele, 1994,McPhee and Miller, 1995,Nordin and Banzhaf, 1995] follows from the protective role of
non-functional code outlined above. Large programs containing a lot of non-functional
code are more likely to survive crossover or mutation with no change to their function
than smaller programs or programs with less non-functional code. Therefore, these
programs have a higher replication accuracy. Given that their behaviour is less likely
to change as a result of crossover; and given that behavioural changes resulting from
crossover tend to be negative; these programs are more likely to be the parents of
viable children; and hence will become better represented in the next generation than
smaller programs and programs with less non-functional code. Consequently, there is
selective pressure for programs to become larger. Furthermore, child programs derived
from programs with high replication accuracy are themselves likely to be good
replicators (they have high effective fitness, to use Banzhaf et al.'s
terminology) and will pass this trait on to their
descendants.
The removal bias theory of bloat [Soule et al., 1996] also appeals to the
disruptive effect of sub-tree crossover. Following crossover, the behaviour of a child
program is more likely to be like its parent (and therefore more likely to be viable)
if the sub-tree being replaced occurs near the bottom of the parent parse tree. This is
because: (a) components lower in a parse tree have less influence upon the program's
outputs; and (b) non-functional code tends to occur at the bottom of parse trees.
Consequently, the sub-tree which is replaced is likely to have below average size.
However, there are no similar constraints upon the size of the sub-tree with which it
is replaced; meaning that the existing sub-tree is more likely to be replaced with a
larger sub-tree. Accordingly, viable child programs are more likely to be larger than
their parents.
The search space bias theory of bloat [Langdon and Poli, 1997] does not appeal to the
behaviour of variation operators. To use Langdon and Poli's
own words: äbove a certain size threshold there are exponentially more longer programs
of the same fitness as the current program than there are of the same length (or
shorter)." Accordingly, it is more likely that evolutionary search will explore those
programs which are longer than those which are of the same length or shorter. A similar
argument is made by Miller [2001], who believes that bloat is caused by evolution
exploring a program's neutral variants: most of which will be larger than the existing
program. The operator bias theory of bloat suggests that certain variation
operators aggravate this effect through innate imbalances which cause them to sample
larger programs (see, for example, [McPhee and Poli, 2001]).
6.5 Expressiveness
Expressiveness is the capacity for a representation to express appropriate programs.
Evolvability is the capacity for a representation to evolve appropriate programs. For
GP, these two issues are related: it is not possible to evolve a program which can not
be expressed and it is not possible to express a program if it can not be evolved by
the GP system. Clearly, both of these issues are important. For GP to be successful, it
must be able to both search the appropriate region of the search space, i.e. express
programs in that region; and be able to get to the appropriate region of the search
space from those areas covered by an arbitrary starting population, i.e. evolve
programs in that region. Furthermore (and certainly in the software engineering
community), expressiveness is seen as a property which encourages evolvability; since
if a program can be expressed, it can also be evolved by making a certain number of
changes to an existing program. Nevertheless, expressiveness in itself is not
sufficient to produce evolvability; since although it may make it possible to evolve a
certain program, it does not necessarily make it easy to evolve the program.
Despite these relations, in GP research expressiveness and evolvability are often
treated as different, sometimes conflicting, design goals. Improving expressiveness can
increase the scope of GP by making it possible to evolve a greater range of programs or
particular types of programs. However, in doing so it changes the search space of GP;
and this can make it harder to evolve a program to solve a particular problem. Indeed,
for a particular kind of problem, there is probably a trade-off between the
expressiveness of the representation and its evolvability - even though in practice a
knowledge of the problem domain would be required to make this trade-off.
Nonetheless, expressiveness is an important topic in GP and it does share a number of
issues in common with the study of evolvability in GP. In recognition of these facts,
this section provides a flavour of some of the approaches which have been taken to
improve the expressiveness of GP. However, it does not attempt to be an exhaustive
reference and, although the issue of evolvability is discussed at length in the next
chapter, it does not attempt to artificially separate the concerns of expressive and
evolvable representations.
So far the term representation has been used somewhat generically to refer to
the way in which a program is presented to the evolutionary mechanism of the GP system.
For the remainder of this chapter, the term is used in a more restricted sense to mean
the format or structure of the program rather than the language it is written in. The
term representational language (taken from Altenberg [1994]) is used to
refer to the language within which a program is expressed. This section is organised
into two parts; separating those approaches which are primarily motivated by a desire
to change the representational language from those which are primarily motivated by a
desire to change the representation of GP.
6.5.1 Linguistic Approaches
This section introduces a selection of GP approaches which use languages or linguistic
elements not normally found in GP. The section is split into three parts. The first
part introduces techniques which introduce a notion of type to GP. The second part
discusses the relative merits of using memory and state within GP. The third part
presents GP systems which use particular kinds of programming language.
Type Systems
The use of type systems to limit evolutionary and genetic behaviours was first explored
by Koza [1992] in the form of constrained syntax structures. Most GP systems are
based around the idea of closure: that all data within a program can be interchanged
freely between nodes; constraining the data to be of one type. Introducing typed data
involves re-writing tree generation and genetic operator routines such that generated
and modified programs always obey the rules of the type system. Koza's ideas were
extended in [Montana, 1994,Montana, 1995] by Strongly-Typed GP (STGP), a system
allowing variables, constants, function argument and return values to be of any type,
so long as the exact types are defined in advance. Generic functions were introduced as
a means of avoiding re-writing functions for each data type. When used in a program,
these are instantiated (and remain instantiated) with typed arguments and return
values.
By introducing type constraints and limiting evolution to generating legal trees, STGP
significantly reduces the search space. In Montana's experiments, STGP was shown to
produce superior results to standard GP across a range of moderately hard problems.
This form was reproduced in [Haynes et al., 1996], where STGP was applied to a difficult
agent-cooperation problem. The programs evolved were significantly better than those
produced by GP. In addition to being more effective, the STGP programs also
demonstrated greater generality and readability. The reduced search space meant that
they evolved significantly faster than standard GP programs. However, this reduced
search space also suggests potential problems in domains where the optimal solution is
outside of the constraints imposed by the type system. Here, STGP will not find the
optimum, and it will not be obvious in advance whether the optimum can be found by
STGP.
Another approach to introducing types to GP can be found in Spector's
[Spector, 2001,Spector and Robinson, 2002] PushGP; a form of GP based upon Spector's
custom-designed Push language17. Push is a stack-based language which maintains separate stacks for data
of different types. Functions, whilst generic, operate upon arguments at the top of
whichever stack is currently identified by the system's
TYPE stack; a special
stack which contains type references. Programs comprise a linear sequence of arguments
and functions. Because the stack system de-couples arguments from the functions which
use them, it is no longer possible to apply incorrectly-typed arguments to a function;
and therefore there is no need to use special syntax-preserving recombination
operators. PushGP performs better than GP upon even-n-parity problems where n > 5; and,
more importantly, scales considerably better for increasing n that either standard GP
or GP with ADFs (Automatically Defined Functions; which are introduced in section
7.3.1).
Memory and State
Conventional GP has no explicit notion of state. The problems it handles are functional
or reactive, based upon simple mappings from input to output. Adding state allows GP to
solve harder knowledge-based problems. The earliest attempt at state was Koza's
progn statement, implicitly handling state via side-effecting terminals. State
can be represented explicitly within programs using either abstract variables or
indexed memory. Indexed memory, in particular, introduces Turing completeness: and is
the motivation behind an approach described by Teller [1994],Teller [1996].
Teller defines memory as an array of integer-holding locations, M-locations wide and
holding numbers between 0 and M. The use of M for both limits prevents evolving
programs from using out-of-range values, since a stored number might be used as an
index elsewhere in the program (and vice versa). This is simpler, and more natural,
than normalising out-of-range numbers. To handle memory-access, two extra non-terminals
are placed into the function set. READ(Y) returns the value at address
Y in the memory.
WRITE(X,Y) places
X at address
Y,
returning the previous value of Y. The low-level approach taken by this
strategy means that no constraints are placed on how memory should be used, and in
theory allows the emergence of more advanced memory models such as indirection. Teller
found a 600% improvement in performance over conventional GP when he applied this
system to a problem requiring state information. However, optimal performance is only
achieved if the memory is the right size for the problem. If M is too small, then
either there is too little state space or the state variables become too close together
in memory18. If M is too large, then information
is easily lost because there is little chance of a read and a write using the same
memory location.
In [Langdon, 1995], Teller's scheme is used to evolve data structures. More
recently, Spector and Luke [1996] have taken Teller's indexed memory and used it to confer
a notion of culture within an evolving GP system. Culture is the non-genetic transfer
of information between individuals. In natural systems, this provides a means of
communication, both within and across generations, which is faster and more open than
normal genetic evolution. In this approach, culture is expressed as a common indexed
memory which any member of any generation can access using Teller's standard functions.
Spector found the use of culture to improve performance upon a range of reactive
problems. In theory, culture should allow various co-operative or competitive
strategies to evolve. Furthermore, it allows an individual to communicate with itself
across generations and even across fitness cases. Spector also noted that, for all the
reactive problems he tried, Teller's GP performed worse than standard GP without
memory; suggesting that memory should only be used for problems which cannot be solved
without it. Presumably this is due to the increased size of the search space caused by
the presence of the extra READ and
WRITE functions.
Language
A number of GP systems attempt to evolve programs in specific languages, or specific
types of language. Yu [Yu and Clack, 1998,Yu, 1999], for instance, describes a GP system based
upon a functional programming approach. The motivation behind this approach was to make
use of the implicit structural abstraction available within functional languages.
Structure abstraction is based upon the use of higher-order functions; a motif common
in functional programming where a function is passed as an argument to another
function. The function passed is defined as a l-abstraction: an anonymous
reusable module. By introducing a minimal type system, crossover is forced to preserve
the bi-layer l-abstraction/higher-order function motif. Structure abstraction
occurs because genetic manipulation still allows the content of both layers to change.
During evolution, l-abstractions are generated dynamically. Higher-order
functions typically apply a l-abstraction recursively over a data structure; an
effect called implicit recursion. This high-level behaviour, linked to controlled use
of recursion, allows the complexity of some hierarchical problems to be reduced to a
simple linear problem; though the success of this approach depends upon user-definition
of appropriate higher-order functions.
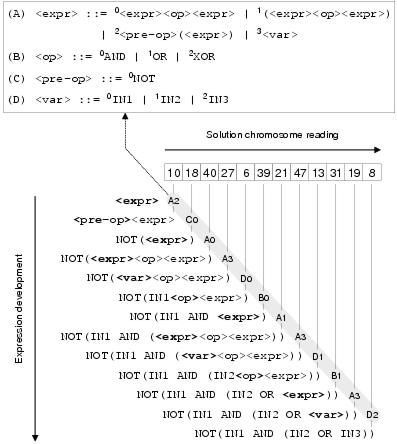
Figure 6.4: Grammatical evolution. A series of numeric values are translated into an expression.
At each stage, the current grammar rule is determined by the left-most
non-terminal (highlighted in bold) and the transition is given by the modulus of
the current chromosome value divided by the number of transitions in the current rule.
For example, at the beginning of translation; rule A is determined by
<expr>
and transition 2 (<expr>::=<pre-op><expr>) is given by the remainder of 10/4.
A more general approach to specifying the language in which programs are represented is
taken by grammatical evolution [Ryan et al., 1998]; where the representation language is
described by a Backus Naur Form grammar and programs are expressed as a series of
grammar transitions. An example of a grammatical evolution solution chromosome, the
language in which it is written, and the process by which it is translated into a
program expression, is shown in figure 6.4. Note that
if the program expression still contains non-terminals when the end of the solution
chromosome is reached, translation returns to the beginning of the chromosome. This can
presumably lead to very efficient solutions for a limited class of problems; although
in the example, a chromosome of length 12 is needed to describe an expression
containing 6 components. Nevertheless, grammatical evolution is a popular approach and
has been shown to out-perform conventional GP upon certain problems.
6.5.2 Representational Approaches
This section describes three different, yet related, approaches to adapting the
representation of evolving programs in GP. The first approach involves changing the
architecture of the program. The second targets the executional structure of programs.
The third uses developmental representations.
Program Architecture
Perhaps the simplest adaptation of the standard GP representation is to use a graph
rather than a tree to express the connectivity of a program. PDGP (Parallel Distributed
Genetic Programming) [Poli, 1997] and cartesian GP [Miller and Thomson, 2000] both take
this approach: representing a program as a directed graph in which each node is either
a function or a terminal. Both systems have significant commonality: both have
mechanisms to prevent cycles (when appropriate) and both allow nodes to exist in the
representation but not have any connections to other nodes (the significance of which
is discussed in section 7.4.3). However, the motivation behind these
systems is different. PDGP aimed to use a program model which reflects the kind of
distributed processing that occurs in neural networks. Cartesian GP was originally
designed to evolve both the functionality and routing of circuits on FPGAs: requiring a
representation in which components were laid out on a grid - and which incidentally
could be interpreted as a graph structure. Both methods show performance improvement
within certain problem domains; and both tend to evolve smaller, more efficient,
programs (a behaviour which is discussed in more detail in section
7.3.2).
A number of GP systems [Angeline, 1998a,Silva et al., 1999,Ferreira, 2001] take a two-layer
approach to representation in which one layer describes a collection of parse trees and
a higher layer describes how these parse trees interact to perform some unified
processing. The earliest of these is Angeline's MIPs (Multiple Interacting Programs)
[Angeline, 1998a] representation. A MIPs net (named to reflect its structural
similarity to a neural network) can be interpreted as a graph in which each node
corresponds to a parse tree. A number of nodes are designated output nodes; and the
outputs of their corresponding parse trees determine the output behaviour of the
program. Connections between nodes are realised by references to the outputs of other
nodes appearing internal to parse trees. In theory, these connections may be
feed-forward or recurrent and have synchronous or asynchronous updates; although
Angeline limited his experiments to synchronous recurrent MIPs nets. Applied to a
number of problems, his approach demonstrated better performance and better solution
generality. Applied to a problem whose solution required memory, the system evolved a
particularly efficient solution which made use of the representation's implicit ability
to store state. Similar observations have been made by Silva et al. [1999] in the context
of their Genetically Programmed Network approach; which uses a representation broadly
similar to Angeline's MIPs representation. Ferreira's GEP (Gene Expression Programming)
[Ferreira, 2001] also makes use of multiple parse trees; though the meaning and
connectivity of these parse trees is determined by the fitness function and is not
evolved by the system. Perhaps what is most interesting about GEP is the way in which
parse trees are encoded: a pre-fix variant which the author believes to be particularly
supportive of variation operators. GEP also shows significant performance gains over
standard GP (although the author's `marketing' style of writing makes it hard to work
out exactly why this is the case): and is the only one of these approaches to have had
a notable impact on the GP community; even though the other two approaches are perhaps
more behaviourally interesting.
Executional Structure
Many of the GP systems introduced in section 6.5.2 use
representations which implicitly change the manner in which a program's executional
structure is represented. In conventional GP, the effect of a component upon execution
is determined by its location within a parse tree. By comparison, in PushGP there is
considerable decoupling between the location of an instruction or argument in the
representation and its temporal role within the program's execution. This occurs
because arguments and results can be stored within stacks and used later; or even not
be used at all. A similar argument applies to other forms of GP which use linear
representations; such as AIMGP19 (Automatic
Induction of Machine Code with Genetic Programming) [Nordin, 1994] which represents
programs as a sequence of machine code instructions, each of which is able to save and
load values from register locations. In this case the registers provide the means for
decoupling instruction location from instruction behaviour. In fact, any form of memory
or state within any kind of representation can have some effect upon the executional
structure of a program: although in representations such as parse trees this effect is
relatively small.
Whilst for most representations executional ordering emerges implicitly from the
connectivity and behaviour of components, some GP systems use representations which
express execution ordering explicitly. PADO (Parallel Algorithm Discovery and
Orchestration) [Teller and Veloso, 1996] is a complex learning system based upon the
principles of genetic programming. PADO uses a graph-based representation in which each
node describes some processing behaviour and, depending on the result, carries out some
judgement behaviour which decides which outgoing path execution will continue along.
Unlike normal GP, which typically describes fixed expressions, PADO describes
structures which are much more akin to computer programs: containing complex flows of
execution which depend upon the results of internal calculations. PADO has been used
for object recognition tasks, giving an impressive level of performance. GNP (Genetic
Network Programming) [Katagiri et al., 2000,Hirasawa et al., 2001] is a GP approach with a similar
representation to PADO; but which also expresses delays within and between program
nodes. GNP is used to model complex dynamical systems; out-performing conventional GP
on a complex ant-foraging problem [Hirasawa et al., 2001].
Developmental Representations
For most of the approaches described above, a program's representation directly
describes a program. A developmental representation, by comparison, describes
how a program or other artifact is constructed. It only indirectly describes
what is constructed. In the long term, it would seem that development is key to
overcoming the problems currently associated with scalability in evolutionary
computation. For direct (non-developmental) GP encodings, representation length is
proportional to program length. Typically this means that representation length grows
in proportion to problem difficulty, and typically this means an above-linear rise in
the time and space required for evolutionary search - not to mention the fact that
the time required to evaluate solutions also often grows at an above-linear rate. With
developmental encodings, however, representation length normally grows at a
below-linear rate relative to program length: and consequently could lead to better
scalability and better evolutionary performance. However, developmental representations
for evolutionary computation are still in their relative infancy and are yet to show a
demonstrable performance advantage. Nevertheless, research in this area has led to a
number of interesting ideas and some promising insights.
Developmental representations are based around the idea of re-writing systems: starting
from some initial configuration, a series of re-writing rules transforms this
configuration through a number of steps which eventually lead to the developed
artifact. Grammatical evolution is a simple example of this approach. However, many
approaches are modelled upon biological growth processes
[Boers and Kuiper, 1992,Gruau, 1994,Koza et al., 1999,Haddow et al., 2001,Downing, 2003,Miller and Thomson, 2003]. A number of
these have been applied to genetic programming (especially circuit evolution)
[Haddow et al., 2001,Downing, 2003,Koza et al., 1999,Miller and Thomson, 2003]. Miller and Thomson [2003] use a
developmental model in which a single starting `cell' is iteratively replicated to
generate a pattern of interacting cells in which both the pattern of interaction and
the behaviour of each cell is decided by a single evolved cartesian GP program.
Following development, the cellular pattern is interpreted as a digital circuit where
interactions represent wires and cellular behaviours represent gates. Whilst distinctly
unsuccessful from a performance perspective, this system is apparently capable of
evolving partially generalised solutions to the even-n-parity problem; where n is
determined by the number of iterations allowed during circuit development.
Downing [2003] describes a developmental program representation based upon
Spector's Push language (described in section 6.5.1). In Downing's
approach, which is based upon a cellular colony metaphor, both development and
execution are determined by a single Push program. Each cell has its own code and data
stacks. The generation of new cells and interaction between cells is achieved through
special language primitives. Inter-cell communication is achieved through primitives
that re-direct function outputs to stacks in other cells. Downing gives examples of how
particular Push programs lead to emergent processing behaviours within the resulting
cellular ecologies. Whilst intended to be used within an EC framework, results
regarding evolutionary behaviour and performance have yet to be published.
6.6 Summary
Genetic programming (GP) is an evolutionary computation approach to automatic
programming: using a computational model of evolution to design and optimise computer
programs and other executable structures. GP is mechanistically similar to the genetic
algorithm and other population based search algorithms. Whilst GP has been successfully
applied within a wide range of problem domains, the method has certain behavioural
problems which limit its performance and scalability. Perhaps the most significant of
these is the failure of its recombination operator, sub-tree crossover, to carry out
meaningful recombination; limiting the capacity for co-operative interactions between
members of the population. Sub-tree crossover is also thought to play a substantial
role in the un-controlled program size growth phenomenon known as bloat.
In addition to reviewing conventional GP, this chapter has introduced a selection of
derivative GP approaches which attempt to improve the behaviour or scope of program
evolution by increasing the expressiveness of the representation used to represent
programs. The next chapter continues this look at derivative GP approaches by
presenting a range of techniques which aim to improve the evolvability of the GP
program representation.
[Contents] [Next Chapter]
Footnotes:
15Hence the term genetic programming is also
sometimes used to refer to versions of Koza's GP used to evolve entities other than
programs: for example, engineering structures; some of which can be described with the
same representation that Koza's GP uses to represent programs.
16Although in most implementations, the programs in the initial population are
biased towards certain shapes and sizes in order to maximise search space coverage.
17The Push language is actually designed to support
auto-constructive evolution systems, such as Pushpop, in which programs describe and
evolve their own reproduction operators. However, this work is outside the scope of
this thesis.
18This is called the `tight representation problem', usually found in codes
when adjacent states have very different representations. For instance, in binary 7
(0111) is very different to 8 (1000). A similar problem occurs here when state
components are forced too close together. Introducing redundancy, in both indexed
memory and in codes, alleviates this problem.
19AIMGP and its predecessors were originally developed
to make the evaluation phase of GP faster. Nevertheless, such approaches also have
benefits for evolvability. These are discussed in proceeding chapters.
Translated in part from
TEX
by
TTH,
version 3.59 on 20 Apr 2004, 14:31,
� Michael Lones 2003
This page uses Google Analytics to track visitors. See Privacy Statement.