Firewire frame processing on GPUs and CPUs
Posted on November 6, 2015In the EPSRC funded Rathlin project, we are investigating remote embedded image processing by using and optimising high level languages for FPGAs e.g. (Stewart, 2015), GPUs and multicore CPUs. This post describes our work on refactoring one software library and one new library for processing firewire camera frames on GPUs and CPUs, using Haskell on the CPU for coordinating data movement and dynamic CUDA code generation.
Refactoring the dc1394 bindings
We have refactored the bindings-dc1394 library, developed by
Ville Tirronen at the University of Jyväskylä, to expose a new
function withFirewireCamera, which looks like this:
withFirewireCamera :: ISOSpeed -- ^ ISO rating for light sensitivity -> VideoMode -- ^ video mode -> Framerate -- ^ capture frame rate -> CInt -- ^ DMA buffer size -> CaptureFlag -- ^ capture flags -> (Camera -> IO a) -- ^ IO action using a camera -> IO ()
This function detects and initialises an attached firewire camera with
user specified parameters, it executes the user defined (Camera -> IO a) action, then stops the firewire transmission. Here it is being
used in conjunction with the OpenCV binding, to save a
captured frame to a file.
withFirewireCamera ISO_400 Mode_640x480_RGB8 Rate_30 4 defaultFlags $ \camera -> do fromJust <$> CV.getFrame camera 640 480 >>= CV.saveImage "captured.png"
This code initialises an attached firewire camera with an ISO light
sensitivty value of 400, it grabs 640x480 RGB images at a rate of 30
frames per second, with 4 images in the memory ring buffer, using the
default dc1394 capture flags. The initalised camera is passed to
getFrame, the frame is saved to file with saveImage, then firewire
transmission ceases.
Mapping firewire frames to OpenCV and Accelerate
Our firewire-image-io library enables users to process firewire
frames using 1) the OpenCV bindings on CPUs (factored out of Ville
Tirronen's earlier dc1394 bindings), and 2) the Accelerate library for
array processing on CPUs and GPUs.
The accelerate mapping provides the ability to either capture one frame, or multiple frames:
-- | captures one RGB image as an OpenCV image. getFrame :: Camera -> Int -> Int -> IO (Either Error (Array DIM3 Word8)) -- | captures multiple RGB images and applies an IO action to each frame. withFrames :: Camera -- ^ firewire camera -> Int -- ^ width -> Int -- ^ height -> Integer -- ^ number of frames to capture -> (Array DIM3 Word8 -> Int -> IO ()) -- ^ action to apply on each counted frame -> Iteratee (Array DIM3 Word8) IO ()
The OpenCV mapping provides the same functionality.
Edge detection on a GPU
Here is a setup of a Flea2 1.4 MP Color FireWire 1394b camera attached to a desktop Linux host with an Nvidia GTS 250 inside. On the left is a photograph of the setup, on the right is the algorithm's output showing edges of trees, cars, a lamp post, and hedges in the foreground just outside the building.

|

|
Here's the Haskell implementation. It captures 20 firewire frames
using withFrames, offloads the canny edge detection computation to
the GPU with CUDA.run, then the image returned to the CPU is written
to file with writeImageToBMP from the accelerate-io
package.
withFirewireCamera ISO_400 Mode_640x480_RGB8 Rate_30 4 defaultFlags $ \camera -> do
let computation :: A.RGBImageDIM3 -> Acc (Array DIM2 A.RGBA32)
computation = A.map A.rgba32OfLuminance -- convert graycale to RGB image
. fst -- get the resulting grayscale image
. canny 0.7 0.9 -- compute Canny edge detection
. A.map A.packRGBA32 -- convert to 2D RGB (R,G,B) triple
. A.formatFrame 480 640 -- reverse array vector received from ptr
. use -- makes frame available for GPU processing
run_ $ A.withFrames camera 640 480 20 $ \frame frameCount -> do
A.writeImageToBMP
(show frameCount ++ "_out.bmp")
(CUDA.run (computation frame)) -- run on the GPU
Firewire capture & GPU performance evaluation
Runtime code generation, kernel loading and data transfer over the PCIe bus all contribute to non-trivial overheads when using GPU acceleration. The wall clock time of executing computationally simple kernels is therefore dominated by data transfer overheads. Using GPUs for realtime applications only makes sense when kernels are so computationally expensive that realtime requirements cannot be met by a host CPU.
For GPU processing, our firewire-image-io library maps firewire
frames into Accelerate arrays. Unlike the approach of writing CUDA
code directly and compiling before runtime, the edge detector
application's call to CUDA.run generates and compiles CUDA code by
invoking Nvidia's nvcc compiler at runtime
(Chakravarty, 2011). This dynamic code generation
creates an addition runtime cost, though the implementation of
CUDA.run caches invocations of Accelerate derived kernels as
reusable binaries. For computer vision, we might expect dynamic code
generation overheads to be removed after the first frame, if the
computation is the same for every frame.
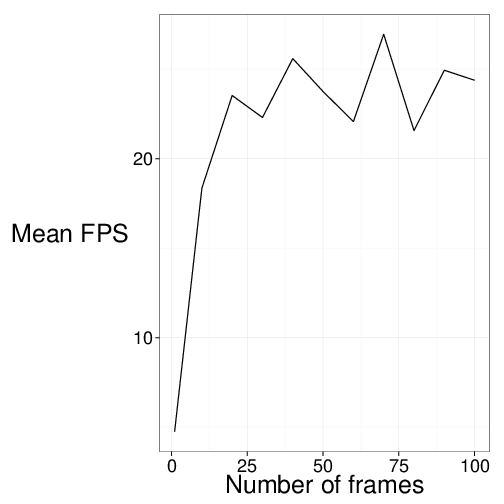
Sure enough, the first frame is processed at a rate of 4 FPS. Once the CUDA binary for our edge detection program is cached, the performance increases to an average of 20 FPS, which presumably is then hitting an IO bottleneck transferring images to the GPU and writing the resulting images to separate files.
Getting the library source code
The source code is on GitHub, firewire camera not included. Code contributions are welcome!
- bindings-dc1394, which exposes
withFirewireCamera: https://github.com/robstewart57/bindings-dc1394 - The
withFirewireCameraupstream pull request : https://github.com/aleator/bindings-dc1394/pull/1 - firewire-image-io, which contains the firewire OpenCV and Accelerate mappings : https://github.com/robstewart57/firewire-image-io
In order for these libraries to compile, version 0.4.0.0 of the CV binding is needed, which has not been uploaded to hackage (see https://github.com/aleator/CV/issues/55).