Data parallelism with Haskell strategies and OpenMP
Posted on May 29, 2016Haskell strategies versus OpenMP directives
Parallel strategies can be used to split Haskell lists into chunks for parallel evaluation, and C++ arrays can similarly be evaluated in parallel using OpenMP directives.
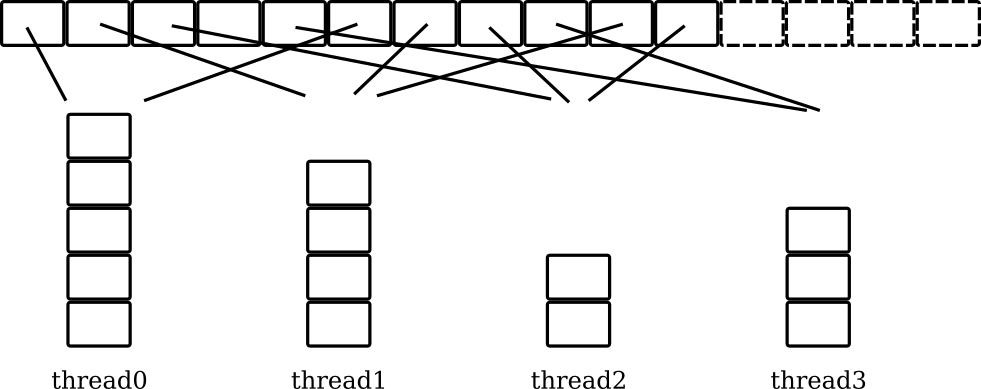
The following code splits a Haskell list into chunks of length i,
and processes the list using function f by assigning chunks across
multiple CPU cores. Allocation to threads at each CPU core is decided
dynamically at runtime, threads steal work from a work queue (a
sparkpool using GHC terminology) to balance load:
parMapChunked strat i f = withStrategy (parListChunk i strat) . map f
newList = parMapChunked rseq 1000 f [0..199999]The same parallel evaluation of a 1 dimensional C++ array can be achieved using OpenMP directives. As with Haskell, threads steal work to balance load:
#pragma omp for schedule(dynamic, 1000)
for(int i=0 ; i < 200000; i++) {
newArray[i] = f(i);
}Haskell parallel strategies in more detail
The computations at each list element in Haskell are iteration
independent by construction, thanks to the immutability of map over
the list. Let's create a parallel strategy on lists…
parMapChunked
:: Strategy b -- ^ evaluation degree at each element
-> Int -- ^ chunk size
-> (a -> b) -- ^ function to apply to each element
-> [a] -- ^ input list
-> [b]
parMapChunked strat i f = withStrategy (parListChunk i strat) . map fThis parallel strategy for list evaluation can then be used like this:
let newList = parMapChunked rseq 1000 addFive [0..199999]Which splits the [0..199999] list into 200 lists using the chunk
size 1000. The strategy rseq evaluates each application of addFive
to weak head normal form. After that, we sum all elements in newList
and print the results:
let sum = foldl' (+) 0 newList
print sumC++ OpenMP directives in more detail
We can do something similar in C++ using OpenMP directives.
#pragma omp for schedule(dynamic, 1000)
for(int i=0 ; i < 200000; i++) {
newArray[i] = addFive(i);
}Using the omp pragma, each each thread executes a copy of the code
within the loop body. The internal OpenMP work queue gives a
chunk-sized block of loop iterations to each thread. When each OpenMP
thread is finished processing its assigned chunks, it retrieves the
next block of loop iterations from the top of the work queue. The
dynamic schedule computes which chunks should be assigned to which
threads at runtime, depending on the work load of each thread.
After that, we sum all elements in newArray and print the results:
int64_t sum = 0;
for(int i=0 ; i < 200000 ; i++)
sum += newArray[i];
cout << sum << "\n" ;Visualising parallel threads
Tools like Threadscope for Haskell, or Intel VTune for C++ can be used to visualise the parallel executions across threads. This is a screenshot of the parallel execution of the Haskell parallel strategy.
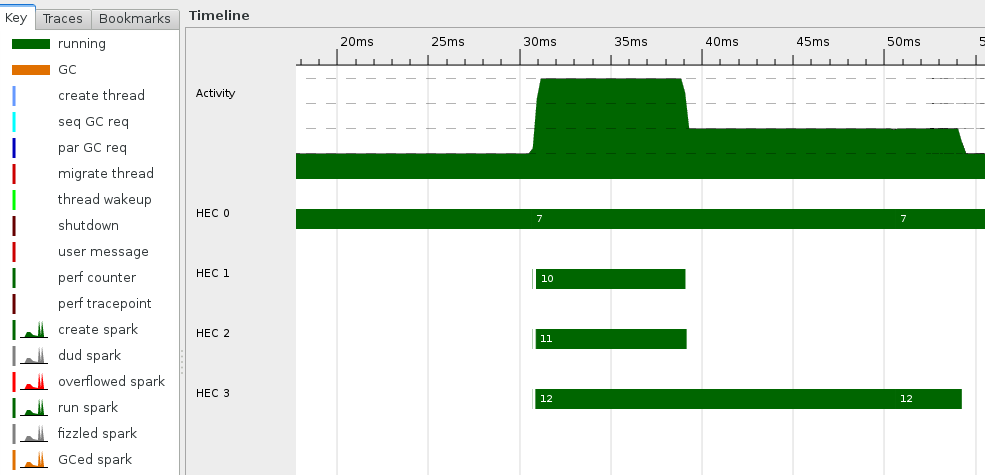
Complete Haskell and C++ source code
Haskell
module Main where import Control.Parallel.Strategies (Strategy,withStrategy,parListChunk,rseq) import Data.List (foldl') parMapChunked :: Strategy b -- ^ evaluation degree at each element -> Int -- ^ chunk size -> (a -> b) -- ^ function to apply to each element -> [a] -- ^ input list -> [b] parMapChunked strat i f = withStrategy (parListChunk i strat) . map f addFive = (+5) main = do let length = 200000 chunkSize = 1000 -- dynamic chunked parallelism newList = parMapChunked rseq chunkSize addFive [0..length-1] -- accumulate the result sum = foldl' (+) 0 newList print sumC++
#include <iostream> using namespace std; #include <stdint.h> #include "omp.h" int addFive(int i) { return i + 5; } int main() { const int length = 200000; const int chunkSize = 1000; int newArray[length]; /* dynamic chunked parallelism */ #pragma omp for schedule(dynamic, chunkSize) for(int i=0 ; i < length ; i++) { newArray[i] = addFive(i); } /* accumulate the result */ int64_t sum = 0; for(int i=0 ; i < length ; i++) sum += newArray[i]; cout << sum << "\n" ; }